Utku's Blog2024-09-23T19:33:32.664Zhttps://utkuufuk.com/Utku UfukHexoTry, catch, but don't throwhttps://utkuufuk.com/2024/09/20/error-handling-in-typescript/2024-09-20T20:22:22.000Z2024-09-23T19:33:32.664ZThe standard try-catch-throw approach to error handling in TypeScript is not type-safe, making it difficult to explicitly handle different kinds of errors in business logic. This might be okay in small projects where it’s affordable to treat all errors similarly, but it’s not ideal for larger and more complex projects where it’s oftentimes desirable to differentiate between recoverable and unrecoverable errors.
Limitations of standard error handling
Since the caught error is of type unknown in the catch block, we cannot rely on TypeScript in ensuring that all the possible error types are covered. Suppose that we have a function that can fail due to several reasons such as:
Input decode (format) failure
Input validation failure
Unexpected database query result
HTTP request timeout
Other errors thrown by libraries
Some of these errors might be recoverable. Such errors should not bubble up to higher abstraction layers lest they disrupt the entire operation. Instead, they should be gracefully handled by the business logic.
For the sake of the argument, let’s assume that we want our system to recover from DecodeError and ValidationError in the example below:
// may throw DecodeError or ValidationError // (but that's not visible in the signature) const importData = (rawData: unknown): ImportResult => { // … }
// call site try { importData(rawData) } catch (err) { // err is of type `unknown` if (err instanceof DecodeError) { console.warn('Decode error:', err)
// gracefully handle decode error
return }
// oops, forgot to handle ValidationError
throw err }
If we wish to handle certain types of errors explicitly, we must make sure to cover all of them, and we get no help whatsoever from TypeScript. Moreover, if the above function evolves to produce additional types of (recoverable) errors, there’s a risk of forgetting to cover them in all the corresponding catch blocks.
Before we start talking about a better approach, it’s important to note that we cannot completely avoid dealing with thrown Errors. This is because external (third-party and system) function calls will throw Errors, even if our code doesn’t throw at all. Thus, we need to find a solution that can deal with unavoidable (foreign) Errors too.
A simple type-safe alternative
Here’s all the boilerplate needed for this simple yet type-safe error-handling mechanism:
// call site const res = importData(rawData) if (isFailure(DecodeFailure)(res)) { // handle decode failure return } if (isFailure(ValidationFailure)(res)) { // handle validation failure return }
persistData(res) // res must be of type `ImportResult`
Note that all the possible failure types are visible in the function signature. TypeScript will alert us if we fail to cover all the possible failure cases at the call site; we won’t be allowed to pass a variable of type ImportResult | SomeFailure to persistData, which expects an ImportResult.
Dealing with foreign errors
As mentioned earlier, we cannot prevent our dependencies from throwing errors. Therefore, we still need to rely on try / catch blocks to handle those errors. Now comes the crucial principle:
Try, catch, but do not throw.
This means that in our own code we should never throw an Error of our own by extending the Error class. Instead, we should extend Failure and return it.
In try / catch blocks at higher layers of abstraction, we may log errors, return HTTP responses, and so on. At lower layers (i.e. business logic), we may catch a foreign Error and return it as a Failure.
An Error should be converted to a Failureif and only if it needs to be explicitly handled it in the business logic. Assuming that most errors don’t require special treatment, Failures are supposed to be used for a very small subset of errors. In such cases, the conversion should be done at the earliest opportunity lest the Error bubbles up to higher layers.
Here’s an example where a SyntaxError thrown by JSON.parse is converted to a ParseFailure and returned:
throw err // let all other kinds of errors bubble up } }
Since we wish to explicitly handle SyntaxError, we need to prevent it from bubbling up unchecked. By converting it to ParseFailure, we force ourselves to explicitly handle it in our business logic.
Note that in the above example, the way we capture SyntaxError is not type-safe. That’s because catching and matching it (via instanceof) is the only option. On the bright side, anything that uses safeParseJson has a way handle ParseFailure in a type-safe manner.
Failure not based on an Error
A Failure doesn’t necessarily have to be created based on an Error. We can create and return custom Failures in the business logic to represent an event/state/situation that isn’t a part of the happy path. For instance, if the business logic doesn’t allow a certain state, then we could return an IllegalStateFailure rather than throw an IllegalStateError and pray that it is handled properly (if at all) in all relevant catch blocks.
Code style
On top of the lack of type safety, this standard error-handling approach makes the code messier too. To throw different kinds of errors from a function, we have to declare some variables via let instead of const (yikes!), and have a lot of try / catch blocks that clutter the code.
To demonstrate this, compare the following two implementations of importData from the earlier examples:
const validatedData = validate(decodedData) if (isFailure(ValidationFailure)(validatedData)) { returnnew OtherFailure(validatedData) // return a new failure }
// … }
Other alternatives
There are some existing type-safe alternatives to the standard error-handling approach such as Either (from fp-ts) and neverthrow.
However, I prefer this solution because
It’s much less intrusive than the aforementioned alternatives. For instance, using Either will likely expose you to more functional programming than you might be comfortable with.
You won’t have to unwrap the return value in the happy path. With Either and neverthrow, the return value is wrapped with Right and Ok, respectively.
Only 10 lines of boilerplate code, no external library dependencies.
Key takeaways
TypeScript has a severe blind spot in type safety when it comes to standard error handling.
Outside of catch blocks, create custom Failures and return them instead of throwing custom Errors.
Catch and convert an Error to a Failure if it should be explicitly handled. If not (that is most of the time), let it bubble up.
By declaring all the possible Failure types in the signature, you can know much more about the behavior of a function at first glance.
]]><p>The standard <code>try-catch-throw</code> approach to error handling in TypeScript is not type-safe, making it difficult to explicitly haMacOS Keyboard Settings and Shortcuts for Codinghttps://utkuufuk.com/2021/01/17/macos-keyboard-shortcuts/2021-01-16T22:00:08.000Z2024-09-19T21:19:55.688ZSome of the default keyboard settings and shortcuts on macOS simply don’t work for me as a software developer. As soon as I get my hands on a new mac, I change some keyboard settings and shortcuts for general text editing, window management, iTerm2 and some other stuff. I’m going to go over everything I do step by step in this post. I’m sure you’ll find at least some of these tips & tricks pretty useful.
Keyboard Type
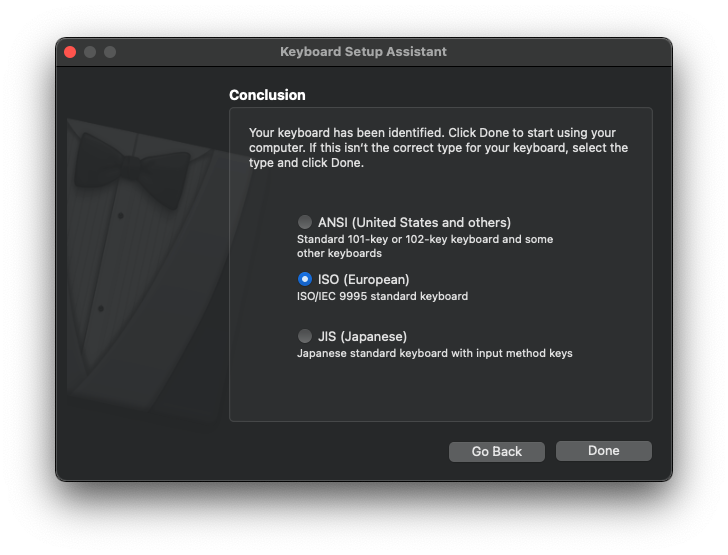
First of all, if you’re using an external keyboard, you should make sure that your keyboard is identified correctly. Usually you don’t have to worry about this, but recently my keyboard was identified incorrectly for some reason while I was setting up macOS for the first time on my new Mac Mini.
You can check the identified keyboard type from System Preferences > Keyboard > Input Sources
If you find out that it’s incorrect, go to System Preferences > Keyboard > Keyboard and select Change Keyboard Type
For me, it turns out my keyboard was identified as ANSI while it’s actually ISO, so I had to change it:
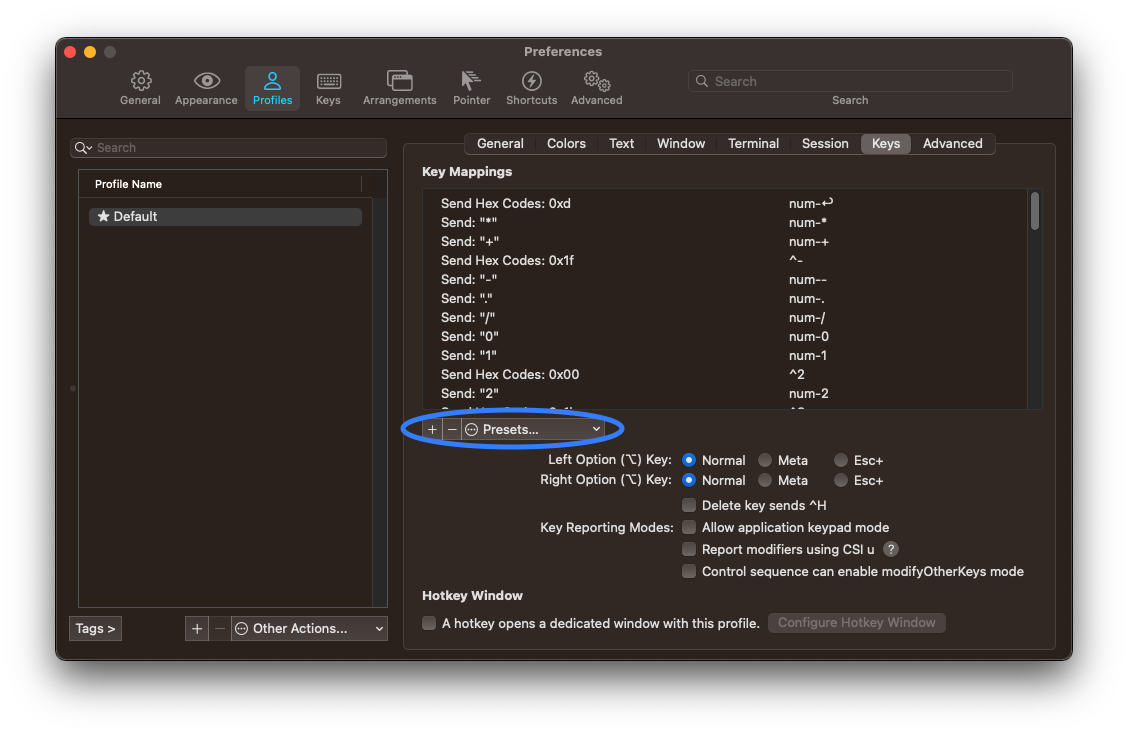
iTerm2 Natural Text Editing
Natural text editing shortcuts such as the ones below do not work by default on iTerm2:
⌥→ (next word)
⌥← (previous word)
⌃→ (end of line)
⌃← (start of line)
You have to set the preset as “Natural Text Editing“ in order to fix this:
iTerm2 lets you create multiple tabs, and you can even split a tab into multiple panes.
⌘T creates a new tab
⌘D creates a new pane by splitting the existing tab horizontally
⇧⌘D creates a new pane by splitting the existing tab vertically
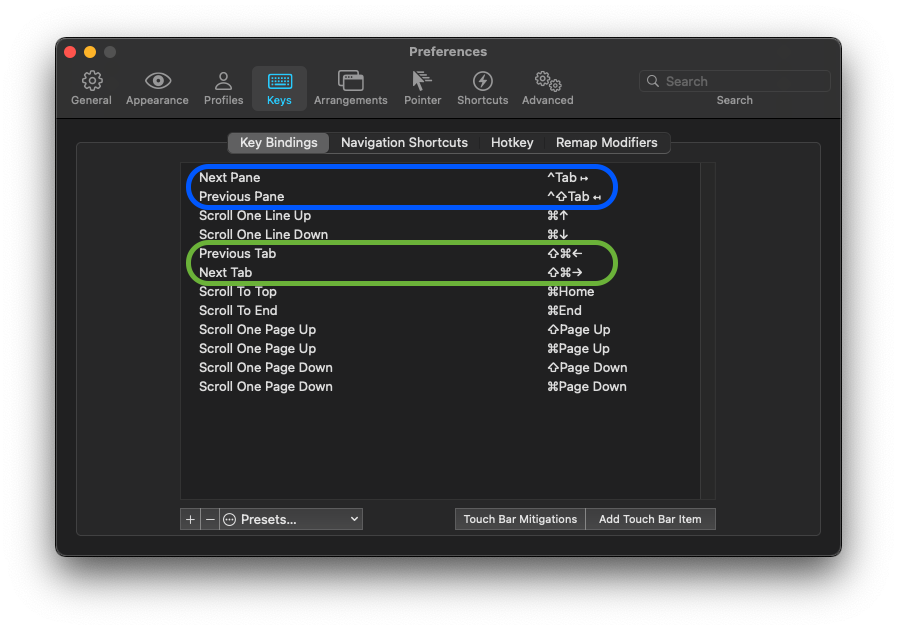
These default shortcuts for creating tabs & panes are pretty nice. However, I don’t like the default shortcuts for switching between tabs/panes. That’s why I override them like this:
iTerm2 > Preferences > Keys > Key Bindings
Switching Between Windows of the Same App
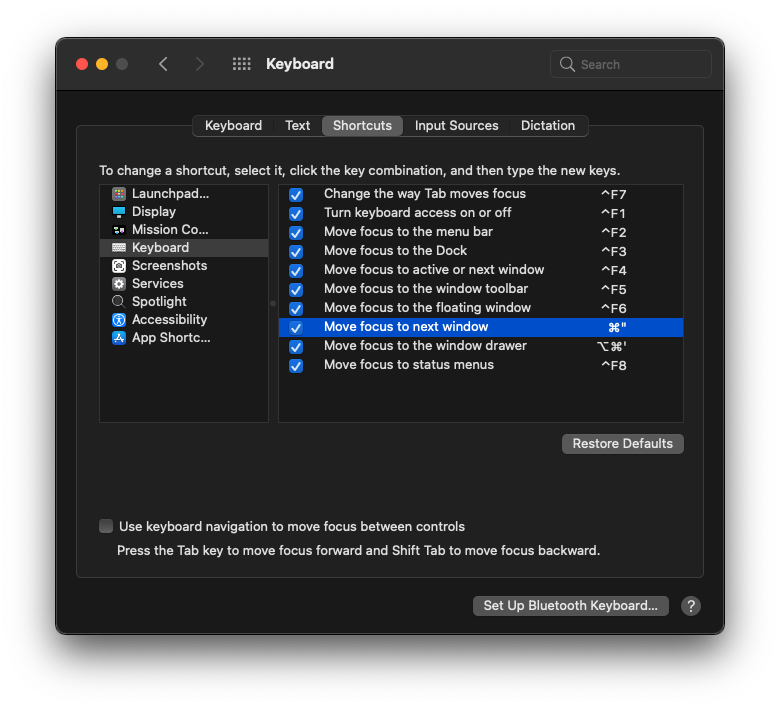
⌘Tab is pretty useful for switching between different apps. What if you need to switch between windows of the same app? Sometimes, I have multiple iTerm2 windows or multiple VSCode windows open at the same time and I want to be able to quickly switch between those. Here’s how you can (re)assign a shortcut for that:
System Preferences > Keyboard > Shortcuts > Keyboard > Move focus to next window
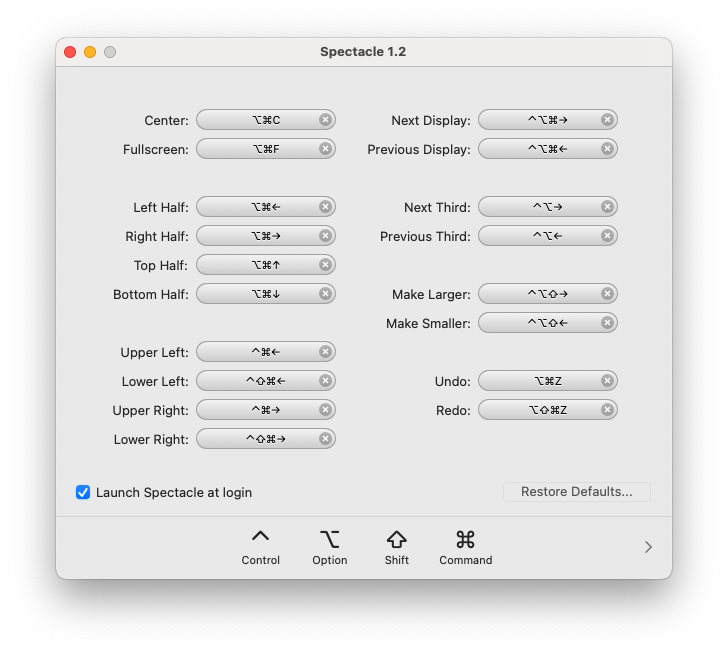
Window Organizer: Spectacle
Spectacle is a free app that lets you organize and resize your windows using keyboard shortcuts:
It’s no longer actively maintained, but I’ve been using it for a couple of years and I’ve had zero issues so far. It’s quite simple, and the default shortcuts are pretty good.
Key Repeat and Delay
I use Vim for text editing, which means I don’t use my mouse to navigate in the text editor. That’s why I frequently need to press and hold some keys for scrolling up/down/left/right in the editor.
By default, key repeat is too slow and the delay until repeat is too long to do that fluidly. I adjust the settings like this, but you should experiment with each option on your favorite text editor and see what works for you the best:
System Preferences > Keyboard > Keyboard
VSCodeVim Extension
You should only read this section if you use both VSCode and the VSCodeVim extension.
Pressing and holding the arrow keys (←, →, ↑, ↓) lets you fluidly navigate between rows (lines) and columns (characters) in the editor by default.
Unfortunately, that’s not the case for Vim equivalents (h, l, k, j). For instance, even if you press and hold the j key, it only advances to the next line and it gets stuck there by default. You have to run one of the following commands after installing the VSCodeVim extension to have the same fluid behavior, as pointed out in the GitHub page of the extension:
1 2 3 4 5 6 7 8 9 10 11
# For VS Code defaults write com.microsoft.VSCode ApplePressAndHoldEnabled -bool false
# For VS Code Insider defaults write com.microsoft.VSCodeInsiders ApplePressAndHoldEnabled -bool false
# For VS Codium defaults write com.visualstudio.code.oss ApplePressAndHoldEnabled -bool false
# If necessary, reset global default defaults delete -g ApplePressAndHoldEnabled
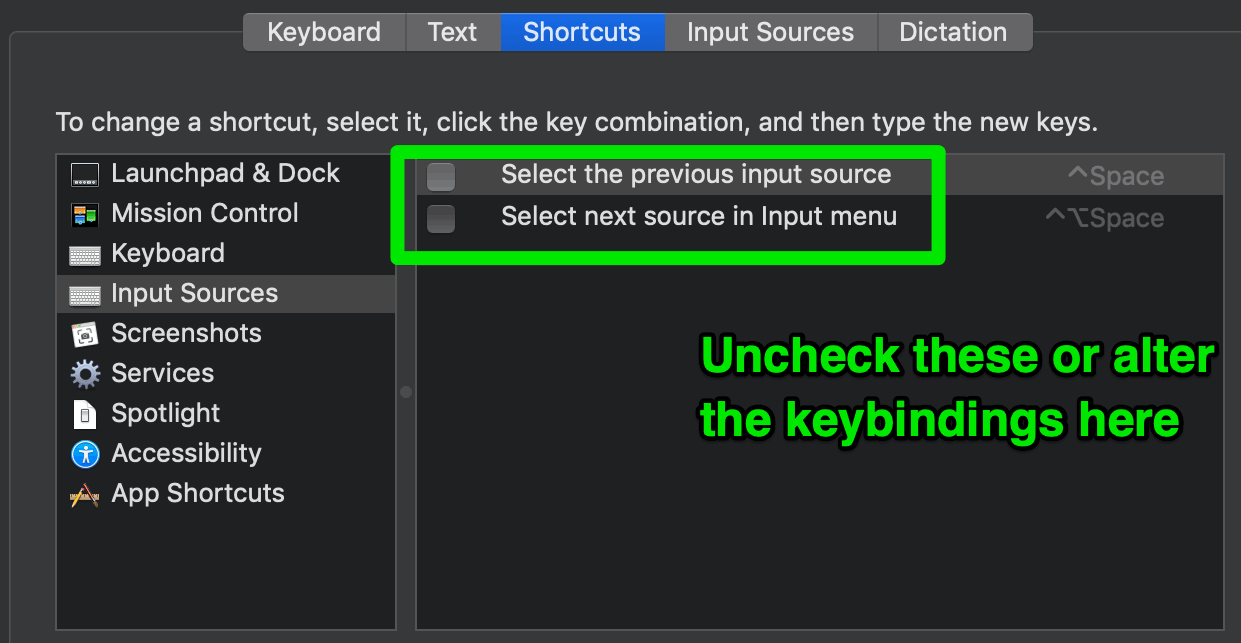
A Handy Shortcut: Control + Space
I think ⌃Space is a very handy key combination and should be assigned to a frequently used shortcut. However, it’s assigned to another shortcut by default, so it needs to be unassigned first.
My command-line shell preference is zsh and one of my favorite zsh plugins is zsh-autosuggestions. It allows you to define a custom hotkey to accept the current suggestion. For me, ⌃Space fits perfectly into this use case.
Bonus: Font Smoothing
I know that this isn’t related to keyboard settings or shortcuts, but I still want to mention it because I think it’s important.
I don’t know about your experience, but the default font smoothing is too much for me. What’s worse is, macOS doesn’t let you change this setting easily from system preferences anymore. You have to actually open the terminal and run this command:
Setting it to 1 works best for me. I suggest you to experiment with each option (0 is lowest, 3 is highest) and see whichever feels best. Keep in mind that in order to see the effects, you have to logout & login back every time you change the setting.
Feel free to leave a comment on Twitter if you have some other tips & tricks that haven’t been covered in this article. I’d love to hear them!
]]><p>Some of the default keyboard settings and shortcuts on macOS simply don’t work for me as a software developer. As soon as I get my hands on a new mac, I change some keyboard settings and shortcuts for general text editing, window management, iTerm2 and some other stuff. I’m going to go over everything I do step by step in this post. I’m sure you’ll find at least some of these tips & tricks pretty useful.</p>One Task Board to Rule Them Allhttps://utkuufuk.com/2020/06/14/one-board/2020-06-14T15:15:30.000Z2024-09-19T21:47:08.946ZDo you ever feel that the numerous productivity tools you use every day actually cost you more time than they are supposed to save? It sure doesn’t feel right when managing your tasks becomes a non-trivial task on its own. On the other hand, there’s no one-size-fits-all solution when it comes to task managers, so it makes sense to use the right tool for the job. To address this dilemma, I recently came up with a simple hack that lets me use all my favorite tools while interacting with just one.
I’m notoriously bad at remembering things, and my life would be a total mess if I didn’t somehow keep track of my personal tasks. Here are some of my favorite tools I use to manage different kinds of tasks:
Even though I like the tools themselves individually, having to keep track of all of them at the same time is a pain in the ass, to be frank. On my computer, I literally have to keep 5 browser tabs open just so that I can see what’s on my to-do list at a given time and decide what to do next. It’s even worse when I’m on a mobile device because then I have to cycle through 5 different apps.
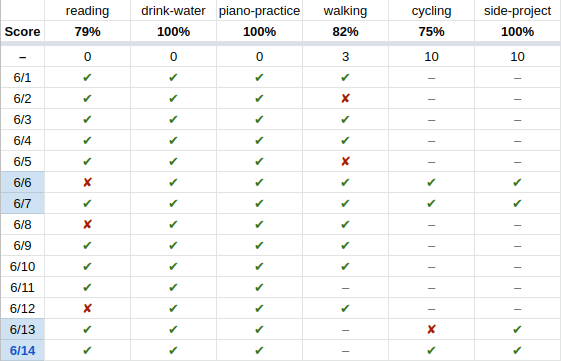
I didn’t want to stop using any of those tools, because each one does a great job in certain situations where others can be insufficient. For instance, I like how Google Sheets allows me to visualize my daily habit progress in a grid. I would have to give up on that if I used Trello for my habits.
This is just a subset of my daily habits :)
Long story short, a few weeks ago I decided to build a tool for periodically grabbing tasks from different sources and putting them in one place. A Trello board seemed to be the perfect place for this because:
UX-wise, it’s my favorite
its API and webhooks make it very easy to build automation tools around it
and let’s face it, who doesn’t like kanbans, am I right?
Here’s how it works:
Query all sources every 5 minutes:
TodoDock: tasks due in the next 2 days — TodoDock API
Github Issues: non-PR issues that are assigned to me — GitHub API
Google Sheets: habits that I haven’t completed yet today — Google Sheets API
Google Calendar:not implemented yet
Create a card in the Trello board for each task that doesn’t already exist.
Check if there are any stale cards and remove them from the board. (e.g. if someone closed a Github issue in the past 5 minutes)
Feel free to check out the source code and let me know what you think! If you can program in Go, it should be fairly easy to fork and customize for your own needs.
But there’s more. The next thing I did was to create a Trello webhook to be fired whenever something changes in the board. Then I set up a Firebase Cloud Function that listens to that webhook and takes a certain action if a card of interest has been archived. I haven’t open-sourced this yet, but here’s the idea:
if a card with tododock label has been archived; reset the corresponding TodoDock task timer
if a card with habit label has been archived, mark the corresponding habit for today as
✘ if it also has the habit-fail label
– if it also has the habit-skip label
✔ if it doesn’t have any other labels
I don’t handle archived cards for Github issues, because the issue gets closed automatically anyway when you merge a pull request that references it.
I can now enjoy the benefits of using all my favorite tools without even interacting with them manually. Sure I check out my personal habits from time to time to see how I’ve done so far, but I don’t need to open the spreadsheet to see my uncompleted habits for the day, or to manually update the sheet when I complete a habit. The same goes for my GitHub issues and TodoDock tasks.
Feel free to reach me out on Twitter for any comments, questions or suggestions you might have. I really like quick hacks like this that save a lot of time and effort compared to how little it takes to code them. So I’m interested in hearing about similar things you’ve come up with that proved useful to you in the past.
]]><p>Do you ever feel that the numerous productivity tools you use every day actually cost you more time than they are supposed to save? It sure doesn’t feel right when managing your tasks becomes a non-trivial task on its own. On the other hand, there’s no one-size-fits-all solution when it comes to task managers, so it makes sense to use the right tool for the job. To address this dilemma, I recently came up with a simple hack that lets me use all my favorite tools while interacting with just one.</p>I had to build a web scraper to buy grocerieshttps://utkuufuk.com/2020/03/28/grocery-scraping/2020-03-28T20:39:26.000Z2024-09-19T21:18:46.625ZGrocery shopping has been one of my least favorite chores, even before the pandemic. Unlike many people I know, I always preferred online shopping over going to the supermarket. Now it’s not a matter of personal preference anymore; everybody stays at home and especially avoids crowded indoor places like supermarkets. It’s good to know that people are acting responsibly, but I never thought this could mean that I won’t be able to do online grocery shopping anymore!
Here’s the deal; very few supermarket chains in Turkey have online stores. Migros Sanalmarket is one of them and it’s arguably the best one. But they don’t have unlimited resources, obviously. When everybody decided to switch to online shopping all of a sudden, they couldn’t handle that demand spike. Even though their delivery system works from 8:30 AM to 10:00 PM every day, it’s virtually impossible to find an empty slot, that is if you play nicely.
I’ve frequently visited the online store for the past two weeks and attempted to place an order, but I always got this message (translated from Turkish):
“We do not have delivery to the neighborhood you have chosen for the next 4 days.”
Probably as soon as new slots are opened, they get occupied in minutes by a few dozen lucky people who happen to be online at that time.
I didn’t want to resort to violence but after yet another failed attempt yesterday, I got really frustrated and finally unsheathed Chrome developer tools. I looked at the Network tab to see which HTTP request was returning the above response. I found out that there was an endpoint for checking live delivery availability, and it was getting hit automatically when a logged-in user visited the website.
The first step of my plan was to write a script that makes a GET request to that endpoint and checks if delivery is available for my neighborhood within the next 4 days. Firsty, I needed to find out what additional information I had to send with my request to make the server treat me as a logged-in user. I looked at the cookies in the Request Cookies section:
The SESSION cookie looks promising, doesn’t it? I did what anybody does when they need to quickly put together a script to get something done; I created a main.py file. The requests package is more than capable of setting cookies and making simple HTTP requests. This is how I tried to get the same response from the server programmatically:
main.py
1 2 3 4 5 6 7 8 9 10 11
import requests
# copy & paste the SESSION cookie value obtained from request headers session = requests.Session() jar = requests.cookies.RequestsCookieJar() jar.set('SESSION', 'Y2IxOWE0YWQtNmM0Ni00ZWYzLTkzYmItOGI4YWQ0MDI1MTg4') session.cookies = jar
# make a GET request to the delivery availability endpoint r = session.get('https://www.migros.com.tr/teslimat/en-yakin-siparis-dilimi') print(r.text)
I got this response:
1 2 3 4 5
<spanclass="part-area date-header mobile-hide pull-right"> <b> Önümüzdeki 4 gün için seçtiğiniz mahalleye teslimatımız bulunmamaktadır. </b> </span>
This is how you say “nope” in Turkish. It was exactly what I wanted to receive. If the session cookie hadn’t worked, or if it hadn’t been enough on its own, I would have received the HTML for a login page. I know because that was what I received when I sent the request without any cookies.
So far so good. I could run a script every minute as a cron job, pipe stdout to a log file and check the logs every once in a while. So I set up the cron job and went AFK for 30 minutes. When I got back, I saw 30 failed attempts.
Obviously, I didn’t want to sit there and check the logs forever. That’s why I decided to use one of my existing Mailgun domains for sending myself an email if and when one of the attempts succeeded. It’s actually pretty easy to send an email using the Mailgun API:
main.py
1 2 3 4 5 6 7 8 9 10
requests.post( os.getenv('MAILGUN_DOMAIN'), auth=("api", os.getenv('MAILGUN_SECRET')), data={ "from": os.getenv('EMAIL_FROM'), "to": [os.getenv('EMAIL_TO')], "subject": "Sanalmarket Is Available!!!", "text": f"Go to {os.getenv('SHOPPING_CART_URL')}" } )
The only issue was that if my script ever found an available slot, it would start sending an email to me every minute until there were no slots left. I really didn’t want to spam myself. As a solution, I made it so that the script would create a .lock file the first time it received a success response and sent me an email. Also, at the beginning of each execution, it would check that .lock file and terminate immediately if it existed.
After adding the email functionality, I went AFK once more and attended to other stuff. I got an email notification on my phone after about an hour later. The sender was me, I was talking about some nonsense that had something to do with grocery shopping. I checked it out anyway. It turned out that Sanalmarket was available for delivery to my neighborhood if I placed an order immediately! I had already prepared my shopping cart, so all I needed to do was confirm the order.
I received my delivery the morning after. I’m pretty sure that I would’ve never been able to get a chance to make an order anytime soon if it wasn’t for that little hack.
That’s all there is to my mini-adventure for this weekend. My script is available on Github for those who are interested. Feel free to reach me out if you have any comments or questions. Also, make sure to subscribe if you’re interested in getting email updates on my future articles.
]]><p>Grocery shopping has been one of my least favorite chores, even before the pandemic. Unlike many people I know, I always preferred online shopping over going to the supermarket. Now it’s not a matter of personal preference anymore; everybody stays at home and especially avoids crowded indoor places like supermarkets. It’s good to know that people are acting responsibly, but I never thought this could mean that I won’t be able to do online grocery shopping anymore!</p>How I Manage My Side-Projects Using Trellohttps://utkuufuk.com/2020/03/20/trello-project-manage/2020-03-20T20:39:26.000Z2024-09-19T21:42:45.811ZFor the last few years, I’ve been spending a lot of my free time working on side-projects. What I came to realize is that it’s quite important that I plan ahead and work in an organized fashion except for very small projects. Trello is one of my favorite software tools ever, and I’m going to talk about how I manage my current side-project using its free version in this article.
Why Tho?
I’m sure some people see this whole side-project management thing as an unnecessary overhead that’s just going to slow them down. But here’s the thing:
At the end of the day, you want to turn a cool idea into reality, on your own. That’s pretty much the meaning of a side-project. However, ideas lead to more ideas, as well as new problems to be solved. Sooner or later your head will explode because of every little thing you have to keep in mind (issues, ideas, problems, suggestions) about your project. If you use something like Trello, you can forget about all that until you have to actually deal with them.
Demo Project: TodoDock
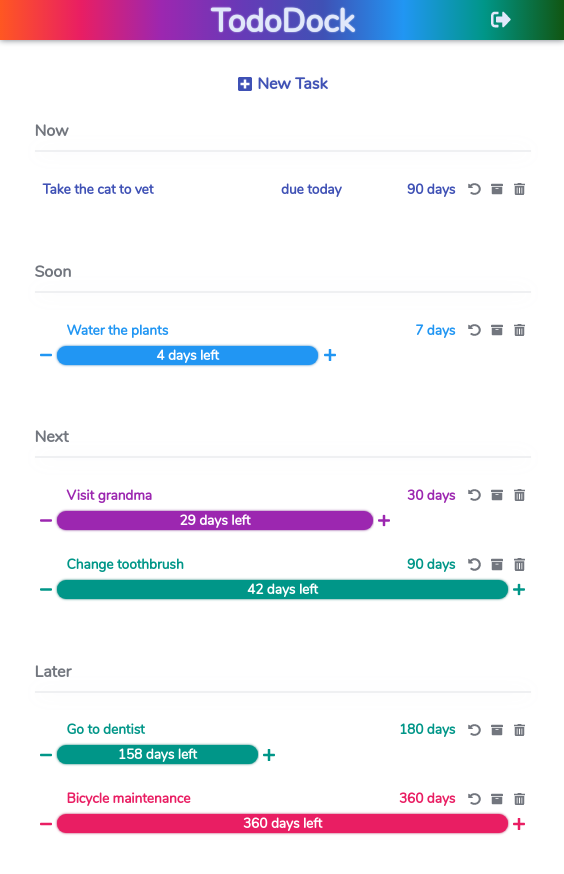
Before talking about how I manage it, let me briefly tell you about TodoDock, the side-project that I’ve been working on for the last few months. In a nutshell, TodoDock lets you keep track of your periodic tasks and sends you a reminder whenever one of your tasks is due soon. The task timers don’t get automatically reset unlike repeating calendar events; you have to reset the timer manually. Therefore you won’t receive another reminder until you’ve actually waited for another full period since the last time you’ve completed the task. Here’s what it looks like:
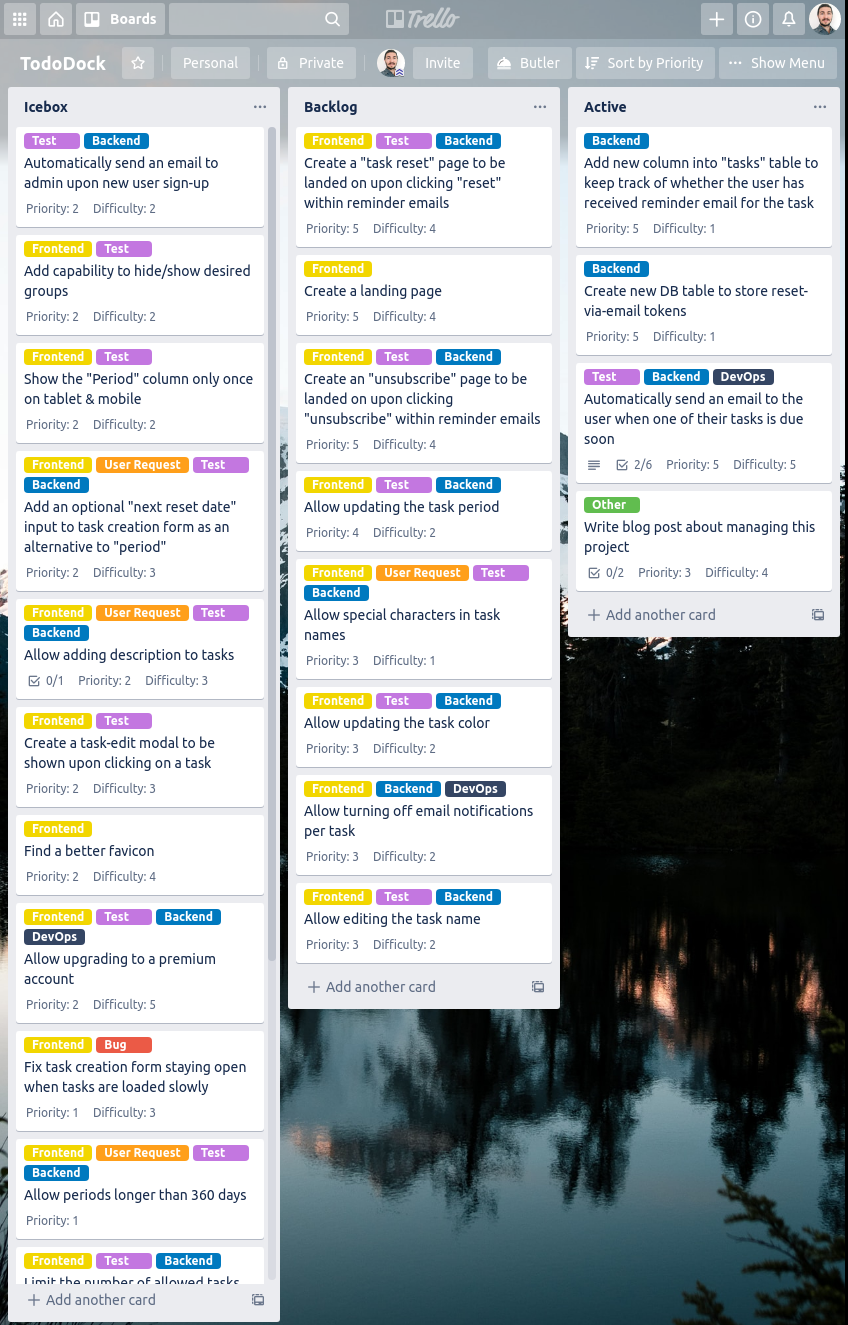
The current state (March 2020) of the app can be categorized as an MVP at best, as there’s still a lot of work to be done. And that’s where Trello comes into play:
Lists
As you can see, I have three lists on the board: Icebox, Backlog and Active. Each task that I’m planning to work on soon is inside one of these. Obviously, the number of lists and the list names can be adjusted according to personal preference, as well as the size & nature of the project at hand. I have this particular setup because
I like to separate high-priority tasks (Backlog) from low-priority ones (Icebox)
I like to see the things I’m currently working on in a separate list (Active)
Cards, Tasks and Labels
Each card is a task. Simple as that. Here’s how I label my tasks:
Backend: server-side coding
Frontend: client-side coding
Test: requires creating new tests
DevOps: server administration/configuration, deployment, CI/CD and so on
User Request: a feature request from one of the existing users
Bug: pest control
Other: none of the above
I assign labels to tasks primarily because then I can estimate their difficulties and priorities more accurately. The difficulty usually ends up higher if it has more than one of the first 4 labels. Similarly, the priority tends to increase if it has a User Request or a Bug label. More on priority and difficulty later…
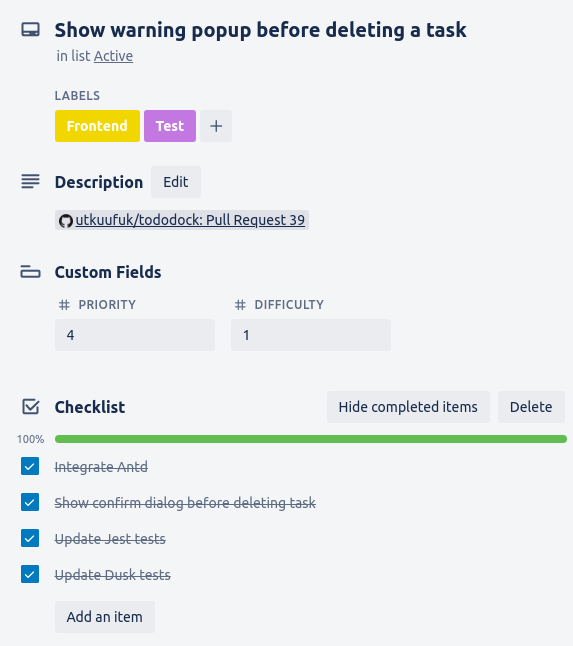
I just archive a task after completing it. I can always view an archived task if I need to. Here’s a task that I’ve archived recently:
I’m a big fan of using checklists to break tasks into even smaller steps. That way I can get a feeling of the progress I’ve made, which helps a lot especially for difficult tasks. Also, I link the Github PR in the description so that it’s easy to see the corresponding changes if I ever want to.
Butler and Custom Fields
There are a bunch of power-ups you can use on your board. You get only 1 power-up per board with the free version. You also get a default power-up called Butler which you can use to bring some automation to your board:
“Free Trello accounts also include a small taste of Butler with limited functionality.”
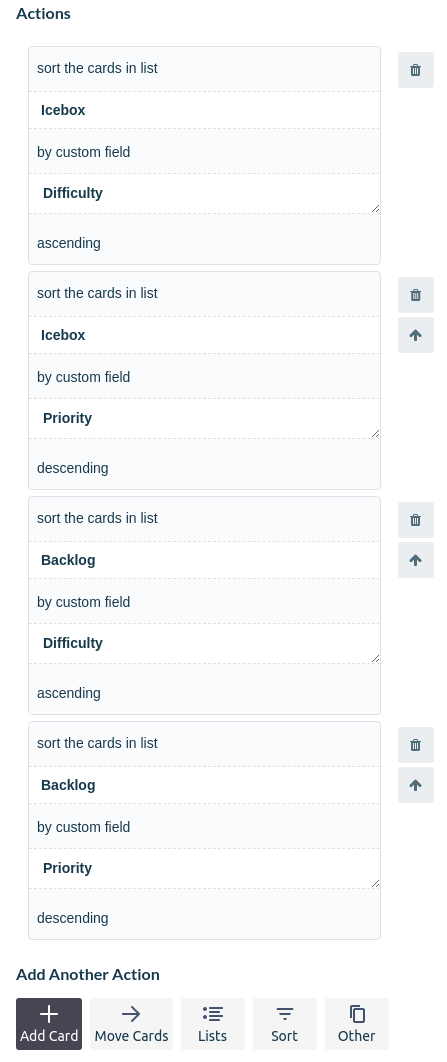
Even that small taste of Butler can actually prove very useful. I used it to define a board button for sorting the tasks by priority and difficulty. You can actually see that button in the board overview screenshot above. It’s called Sort by Priority and it appears next to the Show Menu button.
The problem is, you can’t assign a priority or a difficulty attribute to Trello cards by default. That’s why I spent my power-up slot on Custom Fields, which lets you define … wait for it … custom fields! Combined with Butler, it lets me sort all the cards within each list automatically. Here’s my Sort by Priority command:
You can see that the button triggers a command that runs a sequence of actions, top to bottom. That allows me to sort the equal-priority tasks additionally by their difficulty attributes. If you look at the screenshot of the board again, you’ll see that the tasks in each list are indeed sorted by those rules.
Other Cool Power-Ups
There are a few other power-ups that I would use if I didn’t have to upgrade to a paid account. I’ll just talk about a couple of those, in case some of you prefer them over Custom Fields.
Card Dependencies: It would be great to see if a task blocks (or is blocked by) other tasks. For instance, in my Archive list, there’s a task for automatically sending reminder emails to users. That task is in fact blocked by the two tasks above it, but it’s not obvious that there’s a dependency relationship between them.
Github: This lets you attach pull requests, issues and branches to your cards. You can see visual badges directly from the board view indicating whether a PR has been merged, the status checks and so on.
Bonus Tips & Tricks
Here’s my ten cents, my two cents is free.
When to create new tasks
My board isn’t a complete collection of everything that needs to be done. I create new tasks only when they become obvious to me while I work on the existing ones. Why, you ask?
It’s impossible to think of every little thing in advance, and certainly not fun.
There’s no benefit in creating a task which I’m not going to start working on soon.
I rarely have to delete/update a task if I’ve created it soon before I start working on it.
Deciding what to work on next
I always assign an approximate priority & difficulty to new tasks, because I strongly believe that it’s important to work on what matters the most right now. For example, spending my time on making task groups collapsable (2nd task in Icebox, a nice-to-have visual feature) wouldn’t be a great idea when I haven’t even set up automated reminder emails yet, which is a core feature of TodoDock. So I put the low-priority (<=2) tasks into Icebox and high-priority ones into Backlog. After all the tasks are sorted, I just start working on the topmost task in Backlog, the lowest hanging fruit.
Limiting the task scope
I try to make my tasks as small as possible. I can mention quite a few reasons for that:
Big tasks look scary to get started.
It’s easier to focus on smaller tasks.
It’s easier to write tests for smaller features.
It’s easier to revert a change (using Git) if it has a clear scope.
It’s hard to break big tasks into a few checklist items for progress tracking.
A big task might contain sub-tasks with different priority levels, which can be scheduled independently.
That’s it, I hope you found this useful. Feel free to reach out if you have any comments or questions. Also, don’t forget to subscribe if you want to get notified when I post new stuff.
]]><p>For the last few years, I’ve been spending a lot of my free time working on side-projects. What I came to realize is that it’s quite important that I plan ahead and work in an organized fashion except for very small projects. Trello is one of my favorite software tools ever, and I’m going to talk about how I manage my current side-project using its free version in this article.</p>A Beginner's Roadmap to Becoming a Full-Stack Web Developerhttps://utkuufuk.com/2019/05/12/fullstack-roadmap/2019-05-12T08:57:36.000Z2024-09-19T21:19:21.723ZI’ve been learning about web development for a while pretty much from scratch. I’ve gone over numerous guides, tutorials and documentation from various resources, among which I took note of the important and beneficial ones that I believe a beginner will benefit from the most. In this article, I’m going to share them with you as a roadmap that you can follow if you want to become a full-stack web developer in a fun and efficient way.
Introduction
Let’s make one thing clear. There are lots of programming languages, tools and frameworks out there in the world of web development. In most cases, there’s not a single best way to solve a problem. However, as a beginner, you shouldn’t attempt to learn every new thing for the sole sake of learning, or just because some people are hyped about it. On the contrary, you should aim to acquire the bare minimum skill set so that you can start building stuff as soon as possible.
For instance, you’re going to have to learn JavaScript in order to write browser (front-end) code no matter what. And guess what, there’s something called Node.js which lets you write server-side code using JavaScript as well. Now I’m not arguing here whether Node.js is the best option for developing your back-end or not. However, it’s certainly convenient to be able to build an entire web application by having to learn just one programming language. A deal too good to pass up, don’t you think?
You can (and should) always learn about other technology trends once you master the basics and have a solid understanding of how the web works.
Roadmap
I’m going to divide the steps in this roadmap into several chapters which are sorted below from basic to advanced:
I’m also going to label each item in a category as fundamental, optional or reference. I strongly advise against advancing to a category before completing all the fundamental steps in a previous category. You can postpone optional steps if you want, or skip them altogether if you’re feeling too lazy. References are not meant to be gone through from start to end. You’ll find them useful in the future when you forget some detail and want to quickly look it up, or when you need further information about a specific topic in the corresponding category.
By the way, I didn’t mention this above but if you don’t know how to use Git, stop whatever you’re doing and learn it ASAP. Don’t worry, it’s not going to take long. Actually this 30 min YouTube video is more than enough to get you started. Just make sure that you know how to use the following 7 simple commands for starters:
Lastly I just want to say that if you haven’t used Visual Studio Code yet, you should definitely give it a try. I think it’s an amazing code editor, especially for JavaScript.
Alright let’s begin…
Chapter 1 - HTML & CSS
Learning HTML & CSS is definitely where you want to start as a beginner. Once you have a solid knowledge, these two will let you build structured, elegant and responsive websites with static content such as a blog or a portfolio page. You’ll also use this knowledge in the following chapters where you’ll deal with browser-side JavaScript code or a front-end framework such as React.
Responsive Design Tutorial: Responsiveness isn’t just a nice feature anymore in modern web design, it’s the default.
CSS Grid Tutorial: CSS Grid lets you easily arrange HTML elements in two dimensions on a web page.
Optionals
CSS Flexbox Tutorial: This is a useful yet optional item because it doesn’t really provide any extra functionality if you already know CSS Grid.
SASS Basics: SASS makes it simple to deal with CSS in complex websites. You’ll most likely find it useful in the future, but it’s not mandatory at this point.
HTML and CSS: Don’t try to memorize everything. You can always look it up.
Netlify and Heroku: Come back here when you want to deploy your app.
At this point, I have to also mention some CSS frameworks such as Bootstrap and Materialize. Most people will advise you to learn one because these can really speed up your development process. IMHO this approach isn’t going to help you fully grasp the basics of web design. I think you should stay away from them until you’re comfortable with styling websites with your bare hands.
Chapter 2 - JavaScript
Being the only programming language that can possibly be used on the front-end side, JavaScript is an essential part of web development. As I mentioned earlier, you’re going to be able to develop back-end code with it too, once you learn Node.js as well.
Fundamentals
The Modern JavaScript Tutorial: This is by far the most important item in this list, maybe even in this whole roadmap. It’s going to take some time, but you should absolutely complete at least the first two parts. Since JavaScript is going to be your primary tool as a web developer, you won’t regret investing your time on learning it properly. The good news is, learning JavaScript is fun and you can build cool stuff with it as you learn.
async & await in JavaScript: Promises and async/await might get confusing if you’re not familiar with asynchronous programming. Check this video out after reading the corresponding section in The Modern JavaScript Tutorial in order to see some real action.
Modular Javascript: This one is a bit outdated in terms of JavaScript language features, but it’s still a good tutorial for learning basic design patterns.
RegEx Tutorial 1 and/or RegEx Tutorial 2: While not strictly a JavaScript thing, knowing a little bit of RegEx can make a big difference in your efficiency as a developer.
On a side note, it’s not necessary to learn jQuery unless you have to read and/or modify existing code that uses it. Vanilla JavaScript is equally powerful today except for a few use cases.
Chrome DevTools: This is an excellent reference if you use Chrome developer tools. Besides JavaScript, you can find lots of useful information in it regarding HTML & CSS too.
Chapter 3 - Node.js
Node.js is an asynchronous event-driven JavaScript runtime built on Chrome’s V8 JavaScript engine, which is designed to build scalable web applications. You’ll have acquired the minimum skill set to build an entire dynamic web application after completing this chapter.
Fundamentals
A Beginner’s Guide to NPM: This is a quick guide on how to install and get started with Node.js and the Node Package Manager (NPM).
Express Crash Course: In this video, you’re going to learn about a very popular Node.js framework called Express, which is widely used for developing web applications.
Building a RESTful API with Node.js: An amazing YouTube playlist which walks you through the process of building a practical REST API using Node.js and Express. You’ll also learn how to interact with a NoSQL database called MongoDB along the way.
Optionals
Node.js Presentation: A presentation of Node.js by its original developer Ryan Dahl. Check it out if you want to learn what kinds of problems Node.js has been designed to solve and how it handles I/O compared to some other back-end frameworks.
References
HTTP Reference: Lots of useful information including HTTP request methods, response codes, headers and so on.
Chapter 4 - MySQL
You should’ve learned a little bit about MongoDB in the last chapter if you completed all the fundamentals. Now it’s time to learn some SQL. I think MySQL is a good place to start learning about relational databases.
One thing I would recommend you is, don’t just go with the flow and automatically opt for NoSQL just because everyone is using MongoDB with Node.js these days. This decision requires rational thinking and comparing the pros and cons of each option. There’s a good chance that a relational database is going to fit your needs better for your first real application as a beginner.
Lastly, Object Relational Mapping (ORM), e.g. Sequelize can be tempting to use at first but I say stay away from them before fully grasping SQL. Have a look at this if you want to know why.
Chapter 5 - React
So far you’ve been building your front-end using plain JavaScript. And that’s perfectly fine if you want to become a back-end developer. In that case, please proceed to the next chapter in an orderly fashion.
If you’re still here, we’ve got a little bit of additional work to do. Almost all front-end or full-stack development job openings these days require some knowledge about a front-end framework, particularly either React, Angular or Vue.
At the end of the day, choosing between them really boils down to personal preference unless you want to apply to a specific job. I opted for React after some research, and therefore that’s what I recommend you to learn as well. You might also want to check out some statistics if you’re feeling skeptical about it.
Fundamentals
Intro to React: Learn React by building your own tic-tac-toe game!
Create React App: Learn how to quickly initialize a React project in a Node.js environment.
React Crash Course: Come on now, finish off all the React on your plate.
Optionals
React & Redux Tutorial: This is optional because it might feel a bit repetitive after completing the fundamentals. You still might want to watch this series if you want to learn about Redux.
React Hooks: React Hooks is a relatively new and cool feature, although I don’t think it’s something you absolutely have to learn at this point.
Adding SASS to React: This will only make sense if you haven’t skipped SASS in the first chapter.
Chapter 6 - Docker
Congratulations! You’re now officially a full-stack developer. Go ahead and pat yourself on the back. You must feel like how Neo felt just after he learned Kung Fu. But you still have to complete this chapter if you don’t want to get your ass kicked by Morpheus.
To some of you, Docker might not appear as an absolutely necessary thing to learn. While that’s not incorrect, it’s an investment you’re not going to regret.
Fundamentals
Docker Overview: Just so you know what you’re getting yourself into.
Get Started Part 1 and Part 2: Learn how to set up your Docker environment, build an image and run it as a container.
That’s it, I hope you enjoyed following this roadmap. Don’t forget to subscribe if you want to get updates on my future articles.
]]><p>I’ve been learning about web development for a while pretty much from scratch. I’ve gone over numerous guides, tutorials and documentation from various resources, among which I took note of the important and beneficial ones that I believe a beginner will benefit from the most. In this article, I’m going to share them with you as a roadmap that you can follow if you want to become a full-stack web developer in a fun and efficient way.</p>Using Firebase to Insert Budget Transactions to Google Sheets from Trellohttps://utkuufuk.com/2018/12/20/trello-budget/2018-12-20T14:42:21.000Z2024-09-19T21:44:28.064ZI’ve put together a YouTube Tutorial on building a serverless Firebase application that lets you insert transaction entries into your Google budget spreadsheet just by creating a Trello card from your mobile device. Throughout the the playlist, I demonstrate how to easily create a useful cloud application by wiring together Trello Webhooks, Google Sheets API, Firebase Cloud Firestore and Firebase Cloud Functions.
Feel free to contribute by providing pull requests, issues, ideas or suggestions.
Make sure to subscribe if you want to get updates on my future articles.
]]><p>I’ve put together a <a href="https://www.youtube.com/playlist?list=PL36SguL4LIwmJTYLlnCMXG5Azrpezm4h1">YouTube Tutorial</a> on building a serverless <a href="https://firebase.google.com/">Firebase</a> application that lets you insert transaction entries into your Google budget spreadsheet just by creating a Trello card from your mobile device. Throughout the the playlist, I demonstrate how to easily create a useful cloud application by wiring together <a href="https://developers.trello.com/page/webhooks">Trello Webhooks</a>, <a href="https://developers.google.com/sheets/api/guides/concepts">Google Sheets API</a>, <a href="https://firebase.google.com/docs/firestore/">Firebase Cloud Firestore</a> and <a href="https://firebase.google.com/products/functions/?gclid=CjwKCAiAmO3gBRBBEiwA8d0Q4gWhPtXuV6PN4AxKNiKVEJShrQBMdtLwUtnBxqN16atMTD966oxjXBoC-X8QAvD_BwE">Firebase Cloud Functions</a>. </p>A CLI App to Insert Budget Transactions in Google Spreadsheetshttps://utkuufuk.com/2018/11/10/budget-cli/2018-11-10T09:40:27.000Z2024-09-19T21:44:37.347ZIf you use Google Spreadsheets for personal budget management and also like to get things done from the command line as much as possible, I have some good news for you. I’ve built a CLI app to insert transaction entries in monthly budget spreadsheets with simple commands from CLI. Today I’ll be walking you through the process of building this app.
Monthly Budget Spreadsheet
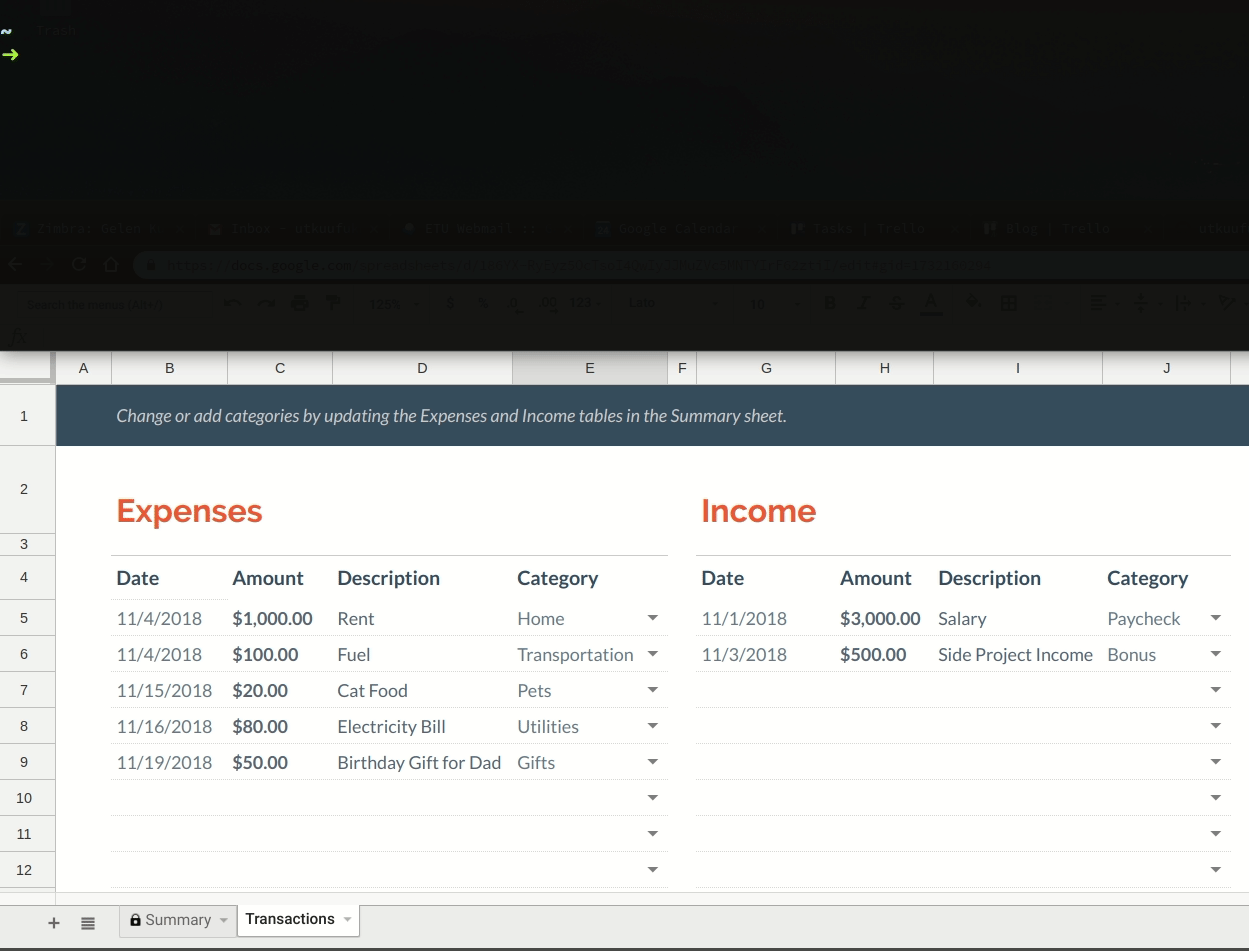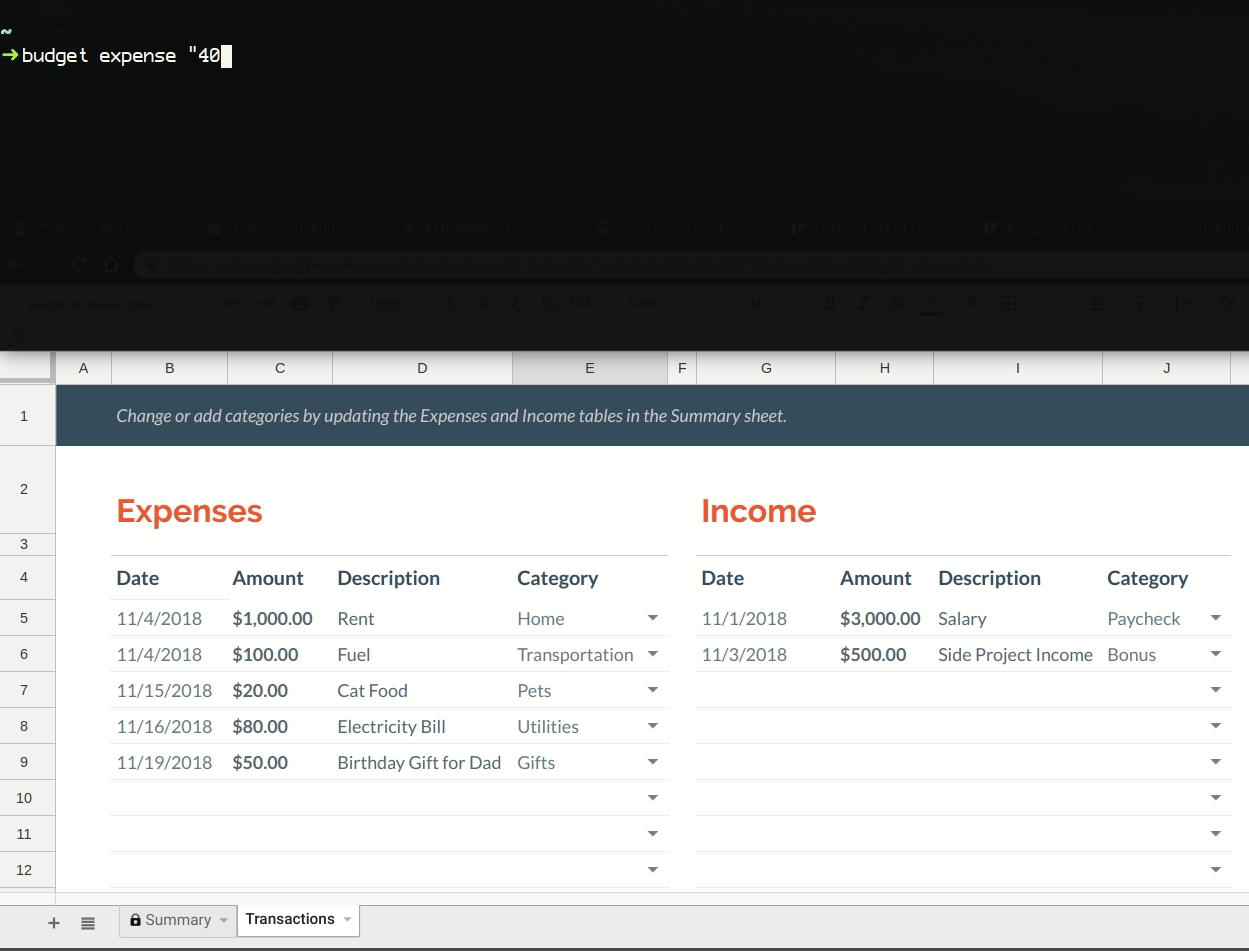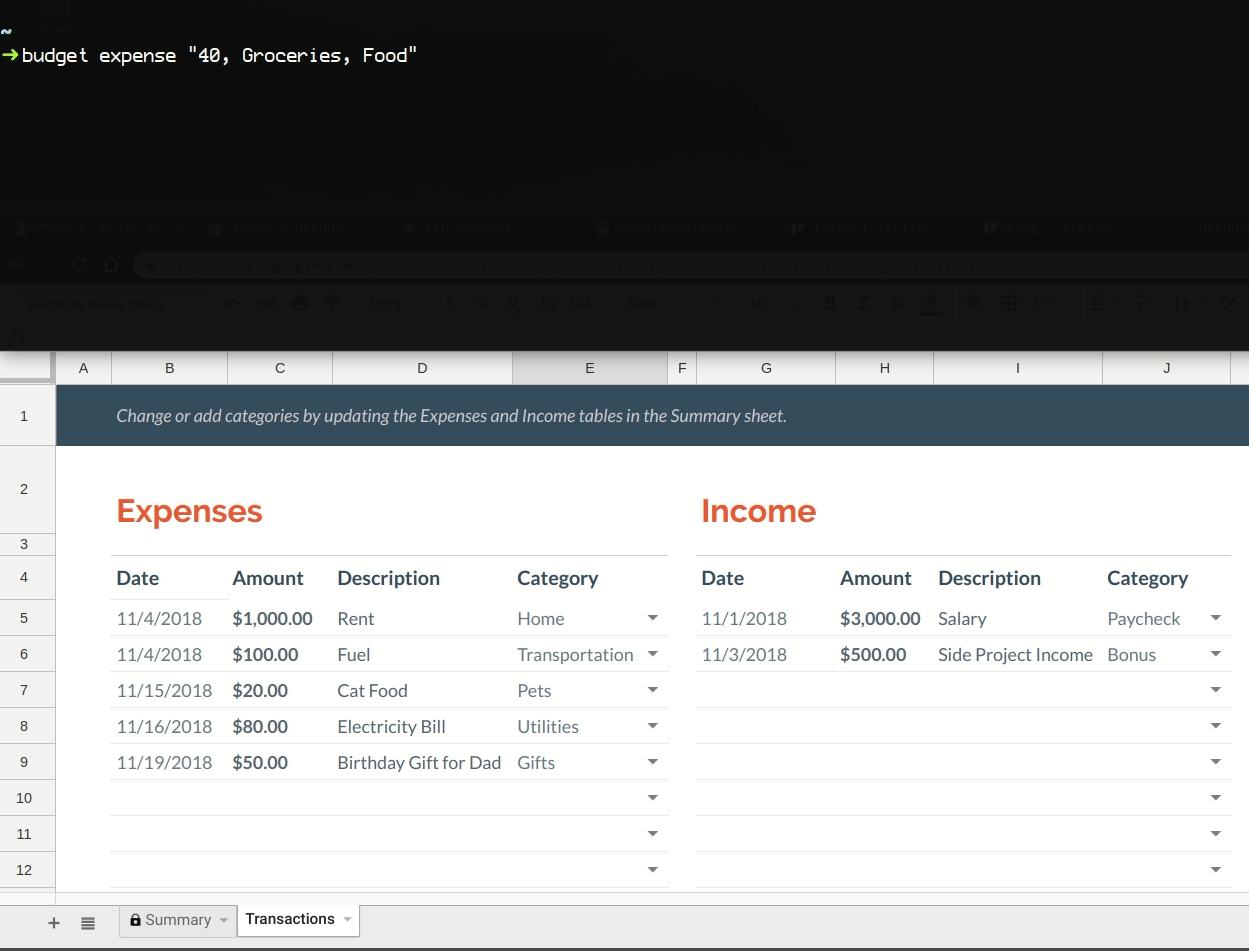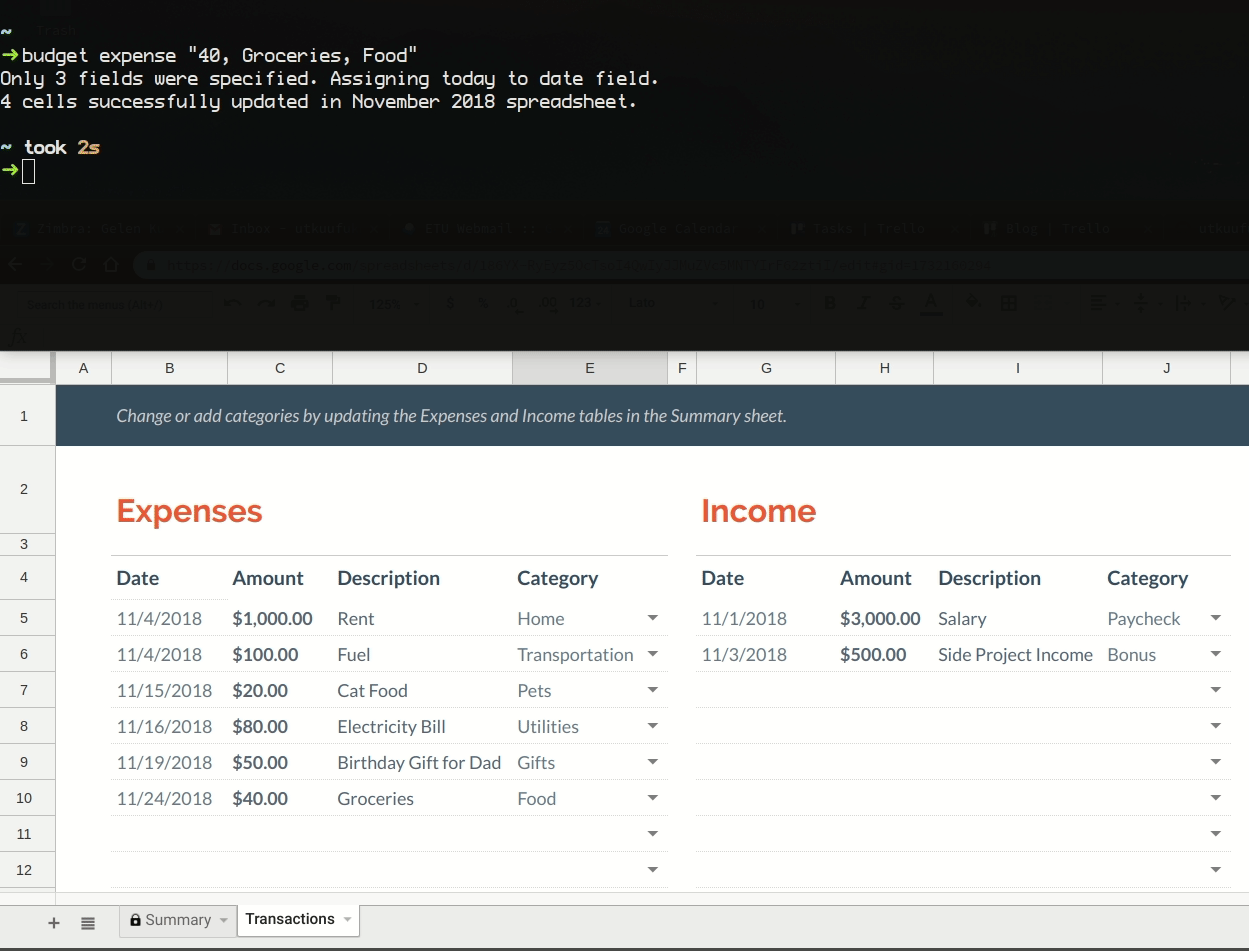
If you don’t have one already, you can go ahead and create a monthly budget template from the spreadsheet template gallery. You can also check out the sample budget sheet that I’ve created to see what it looks like. It’s made up of two pages (sheets):
Transactions page lets you insert expense & income entries.
Summary page lets you keep track of your budget.
The main purpose of this tool is to let you insert entries in Transactions page from CLI, saving you the trouble of opening the actual spreadsheet in a browser.
Take note of this URL or just the SPREADSHEET_ID after you’ve created a spreadsheet because you’re going to need it later. For example, the ID of my sample budget spreadsheet is 186YX-RyEyz5OcTsoI4QwIyJJMuZVc5MNTYIrF62ztiI.
Then you have to simply follow the first 2 steps of this guide which involve
creating a console project to enable the Google Sheets API:
downloading a credentials.json file for authorization:
The next step is to generate an authorization token to access your spreadsheets. The script below will open up a browser and request permission from your Google account to generate a token.json file from credentials.json:
createtoken.py
1 2 3 4 5 6 7 8 9 10 11
from oauth2client import file, client, tools from httplib2 import Http from googleapiclient.discovery import build
store = file.Storage('token.json') creds = store.get() ifnot creds or creds.invalid: flow = client.flow_from_clientsecrets('credentials.json', SCOPES) tools.run_flow(flow, store)
This token needs to be created only once, so it’s a good idea to do it as part of the installation procedure of the app. Let’s create an installation script and run createtoken.py as the first step:
install.sh
1
python3 createtoken.py
Before inserting a transaction entry, our app needs to read token.json and authorize. So let’s create the main script and add this authorization step:
budget.py
1 2 3 4 5 6 7 8 9
#!/usr/bin/env python3 from googleapiclient.discovery import build from httplib2 import Http from oauth2client import file, client, tools
if __name__ == '__main__': store = file.Storage('token.json') creds = store.get() service = build('sheets', 'v4', http=creds.authorize(Http()))
Commands & Parameters
Our app will have 4 commands:
Select Spreadsheet by ID
Select Spreadsheet by URL
Append Expense
Append Income
And here’s how each command is going to be executed by the user:
1 2 3 4 5 6 7 8 9 10 11
# select spreadsheet by ID budget id <SPREADSHEET_ID>
# select spreadsheet by URL budget url <SPREADSHEET_URL>
#!/usr/bin/env python3 from googleapiclient.discovery import build from httplib2 import Http from oauth2client import file, client, tools import sys
if __name__ == '__main__': command = sys.argv[1] arg = sys.argv[2] if command == 'url': start = arg.find("spreadsheets/d/") end = arg.find("/edit#")
# write spreadsheet ID & exit if command is 'id' or 'url' if command == 'id'or command == 'url': ssheetId = arg if command == 'id'else arg[(start + 15):end] withopen('spreadsheet.id', 'w') as f: f.write(ssheetId) sys.exit(0)
# read spreadsheet ID from file if command is 'expense' or 'income' withopen('spreadsheet.id') as f: ssheetId = f.read()
# authorize store = file.Storage('token.json') creds = store.get() service = build('sheets', 'v4', http=creds.authorize(Http()))
# TODO: insert transaction
Notice that SPREADSHEET_ID is written to a file named spreadsheet.id whenever one of the id or url commands is executed. And this file is read while processing the expense and income commands in order to access the selected spreadsheet.
Transaction Entry
First of all, row and column indices of the last entry has to be determined in order to append a new one. To do that, we read rows 5 to 40 from column C or H (depending on the command) and check the number of existing entries. Here 5 is the minimum row index that a transaction can be inserted, and 40 is the index of the last row in the Transactions page. (You should set this to the total number of rows in your sheet.) Then we store the row index to insert a new entry for the current transaction type in a variable called rowIdx:
Now we have budget.py ready in our project folder. However, it has to be executable from any directory via CLI. Therefore we need to make sure that it’s in a directory referenced by the PATH environment variable, such as /usr/bin/.
On the other hand, token.json and spreadsheet.id files do not have to be in PATH. They should be located somewhere owned by the user such as ~/.config/budget-cli/ so that they can be accessed without sudo permission.
We’re going to copy budget.py and token.json in install.sh, and spreadsheet.id will be created inside ~/.config/budget-cli/ automatically when the budget id or budget url command is executed for the first time:
install.sh
1 2 3 4 5 6 7 8 9 10 11
# create token from credentials python3 createtoken.py
# move script to a location in PATH and make it executable sudo cp budget.py /usr/bin/budget sudo chmod +x /usr/bin/budget
# move token.json to a globally accessible location with read access mkdir -p ~/.config/budget-cli cp token.json ~/.config/budget-cli/token.json chmod +r ~/.config/budget-cli/token.json
Notice that I’m renaming budget.py as budget while copying it because I want to use the app like
1
budget <command> <params>
as opposed to
1
budget.py <command> <params>
Note that this wouldn’t be possible without the first line in budget.py, which is:
1
#!/usr/bin/env python3
By the way, let’s not forget to create an uninstallation script to clean up:
Last but not least, we have to slightly modify the file I/O lines in budget.py taking into account the global file locations. You can find the polished and up-to-date version of it in the Github repository. The latest version also has new cool features like logging the transaction history:
That’s it! Just run ./install.sh from the project folder and you should be able to use the app. I hope you enjoyed this little walkthrough. If you’re still here, you should subscribe to get updates on my future articles.
]]><p>If you use Google Spreadsheets for personal budget management and also like to get things done from the command line as much as possible, I have some good news for you. I’ve built a <a href="https://github.com/utkuufuk/budget-cli">CLI app</a> to insert transaction entries in monthly budget spreadsheets with simple commands from CLI. Today I’ll be walking you through the process of building this app.</p>Fast Reddit Scrapinghttps://utkuufuk.com/2018/07/29/reddit-scraping/2018-07-29T19:26:01.000Z2024-09-19T21:24:08.564ZToday I’m going to walk you through the process of scraping search results from Reddit using Python. We’re going to write a simple program that performs a keyword search and extracts useful information from the search results. Then we’re going to improve our program’s performance by taking advantage of parallel processing.
Tools
We’ll be using the following Python 3 libraries to make our job easier:
Before we begin, I want to point out that we’ll be scraping the old Reddit, not the new one. That’s because the new site loads more posts automatically when you scroll down:
The problem is that it’s not possible to simulate this scroll-down action using a simple tool like Requests. We’d need to use something like Selenium for that kind of thing. As a workaround, we’re going to use the old site which is easier to crawl using the links located on the navigation panel:
Scraper v1 - Program Arguments
Let’s start by making our program accept some arguments that will allow us to customize our search. Here are some useful parameters:
keyword to search
subreddit restriction (optional)
date restriction (optional)
Let’s say we want to search for the keyword “web scraping”. In this case, the URL we want to go is: https://old.reddit.com/search?q=%22web+scraping%22
If we want to limit our search with a particular subreddit such as “r/Python”, then our URL will become: https://old.reddit.com/r/Python/search?q=%22web+scraping%22&restrict_sr=on
Finally, the URL is going to look like one of the following if we want to search for the posts submitted in the last year: https://old.reddit.com/search?q=%22web+scraping%22&t=year https://old.reddit.com/r/Python/search?q=%22web+scraping%22&restrict_sr=on&t=year
The following is the initial version of our program that builds and prints the appropriate URL according to the program arguments:
If you take a look at the page source, you’ll notice that all the post results are stored in <div>s with a search-result-link class. Also note that unless it’s the last page, there will be an <a> tag with a <rel> attribute equal to nofollow next. That’s how we’ll know when to stop advancing to the next page.
Therefore using the URL we built from the program arguments, we can collect the post sections from all pages with a simple function that we’ll call getSearchResults. Here’s the second version of our program:
Now that we have a bunch of posts in the form of a bs4.element.Tag array, we can extract useful information by parsing each element of this array further. We can extract information such as:
Information
Source
date
datetime attribute of the <time> tag
title
<a> tag with search-title class
score
<span> tag with search-score class
author
<a> tag with author class
subreddit
<a> tag with search-subreddit-link class
URL
href attribute of the <a> tag with search-comments class
# of comments
text field of the <a> tag with search-comments class
We’re also going to create a container object to store the extracted data and save it as a JSON file (product.json). We’ll load this file in the beginning of our program which may contain data from other keyword searches. When we’re done scraping the current keyword, we’ll append the new content to the existing data. Here’s the third version of our program:
Now we can search for different keywords by running our program multiple times. The extracted data will be appended to the product.json file after each execution.
Scraper v4 - Scraping Comments
So far we’ve been able to scrape information from the post results easily, since this information is available in a given results page. But we might also want to scrape comment information which cannot be accessed from the results page. We must instead parse the comment page of each indiviadual post using the URL that we previously extract in our parsePosts funciton.
If you take a close look at the HTML source of a comment page such as this one, you’ll see that the comments are located inside a <div> with a sitetable nestedlisting class. Each comment inside this <div> is stored in another <div> with a data-type attribute equal to comment. From there, we can obtain some useful information such as:
Information
Source
# of replies
data-replies attribute
author
<a> tag with author class inside the <p> tag with tagline class
date
datetime attribute in the <time> tag inside the <p> tag with tagline class
comment ID
name attribute in the <a> tag inside the <p> tag with parent class
parent ID
<a> tag with the data-event-action attribute equal to parent
text
text field of the <div> tag with md class
score
text field of the <span> tag with score unvoted class
Let’s create a new function called parseComments and call it from our parsePosts function so that we can get the comment data along with the post data:
defparsePosts(posts, product, keyword): for post in posts: time = post.find('time')['datetime'] date = datetime.strptime(time[:19], '%Y-%m-%dT%H:%M:%S') title = post.find('a', {'class':'search-title'}).text score = post.find('span', {'class':'search-score'}).text score = int(re.match(r'[+-]?\d+', score).group(0)) author = post.find('a', {'class':'author'}).text subreddit = post.find('a', {'class':'search-subreddit-link'}).text commentsTag = post.find('a', {'class':'search-comments'}) url = commentsTag['href'] numComments = int(re.match(r'\d+', commentsTag.text).group(0)) commentTree = {} if numComments == 0else parseComments(url) product[keyword].append({'title':title, 'url':url, 'date':str(date), 'score':score, 'author':author, 'subreddit':subreddit, 'comments':commentTree}) return product
Scraper v5 - Multiprocessing
Our program is functionally complete at this point. However, it runs a bit slowly because all the work is done serially by a single process. We can improve the performance by handling the posts by multiple processes using the Process and Manager objects from the multiprocessing library.
The first thing we need to do is to rename the parsePosts function and make it handle only a single post. To do that, we’re simply going to remove the for statement. We also need to change the function parameters a little bit. Instead of passing our original product object, we’ll pass a list object to append the results obtained by the current process.
results is actually a multiprocessing.managers.ListProxy object that we can use to accumulate the output generated by all processes. We’ll later convert it to a regular list and save it in our product. Our main script will now look like as follows:
if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--keyword', type=str, help='keyword to search') parser.add_argument('--subreddit', type=str, help='optional subreddit restriction') parser.add_argument('--date', type=str, help='optional date restriction (day, week, month or year)') args = parser.parse_args() if args.subreddit == None: searchUrl = SITE_URL + 'search?q="' + args.keyword + '"' else: searchUrl = SITE_URL + 'r/' + args.subreddit + '/search?q="' + args.keyword + '"&restrict_sr=on' if args.date == 'day'or args.date == 'week'or args.date == 'month'or args.date == 'year': searchUrl += '&t=' + args.date try: product = json.load(open('product.json')) except FileNotFoundError: print('WARNING: Database file not found. Creating a new one...') product = {} print('Search URL:', searchUrl) posts = getSearchResults(searchUrl) print('Started scraping', len(posts), 'posts.') keyword = args.keyword.replace(' ', '-') results = Manager().list() jobs = [] for post in posts: job = Process(target=parsePost, args=(post, results)) jobs.append(job) job.start() for job in jobs: job.join() product[keyword] = list(results) withopen('product.json', 'w', encoding='utf-8') as f: json.dump(product, f, indent=4, ensure_ascii=False)
This simple technique alone will greatly speed-up the performance. For instance when I perform a search involving 163 posts in my machine, the serial version of the program takes 150 seconds to execute, corresponding to approximately 1 post per second. On the other hand, the parallel version only takes 15 seconds to execute (~10 posts per second) which is 10x faster.
You can check out the complete source code on Github. Also, make sure to subscribe to get updates on my future articles.
]]><p>Today I’m going to walk you through the process of scraping search results from <a href="https://www.reddit.com">Reddit</a> using Python. We’re going to write a simple program that performs a keyword search and extracts useful information from the search results. Then we’re going to improve our program’s performance by taking advantage of parallel processing.<br>Tutorial on Building a Chess Game & AI Using Eclipse RCPhttps://utkuufuk.com/2018/06/17/alpha-beta-chess/2018-06-17T10:13:00.000Z2024-09-19T21:44:52.270ZHi all, I’ve put together a YouTube video series on developing an Eclipse RCP application in Java to build a chess game with a cool AI algorithm called alpha-beta pruning. You need no prior knowledge on Eclipse RCP to follow along, but a basic understanding of the Java programming language would definitely help.
TLDR: Here’s the YouTube Playlist
What Is It?
I started developing the first version of this application a few years ago while learning Java. After a while, I started to learn Eclipse RCP and thought it would be a good idea to build a GUI for my chess game on this platform. Then recently I took an AI course and learned about minimax and alpha-beta pruning algorithms. So I decided to rewrite the application and plug these algorithms in so that I could improve the AI, while recording the whole development process. It took a few months and most of my spare time, and finally it’s complete. I hope you like it!
Who Is It For?
You might like this tutorial if you
are a beginner in Java and want to learn more about the language (or object-oriented programming in general)
want to learn how to build a simple Eclipse RCP application
are interested in watching the whole process of building a chess game from scratch
want to see the minimax & alpha-beta pruning algorithms in action
are NOT looking for a detailed tutorial and discussion focused solely on AI or the alpha-beta pruning algorithm
Playlist Overview
There are a total of 30 videos in the playlist, which is organized as follows:
Video #
Topic
1
Introduction
2 to 11
Coding the building blocks (board, square, piece etc.)
12 to 16
Evaluating the legal moves for different chess pieces
17 to 23
Building the GUI, UX and game mechanics
27 to 30
Implementing the AI (minimax, alpha-beta-pruning & iterative deepening)
Sound Issues
I apologize for the poor sound quality in the first several videos, especially the one after the intro. Unfortunately, I had to use my laptop’s built-in microphone because I didn’t have one. Thankfully the sound gets better after a while because I managed to get my hands on a decent microphone later on.
Contributing
Feel free to check out the github repo if you are interested in contributing. I’m aware that there are lots of missing features such as:
En passant
Pawn promotion
Castling
Check & checkmate (I know…)
Potential optimizations regarding the AI
UX improvements
Make sure to subscribe if you want to get updates on my future articles.
]]><p>Hi all, I’ve put together a <a href="https://www.youtube.com/watch?list=PL36SguL4LIwmhgHkziX-2C91SOTQl1rEL&v=zacLahqmlf0">YouTube video series</a> on developing an Eclipse RCP application in Java to build a chess game with a cool AI algorithm called alpha-beta pruning. You need no prior knowledge on Eclipse RCP to follow along, but a basic understanding of the Java programming language would definitely help.</p>One-vs-All Classification Using Logistic Regressionhttps://utkuufuk.com/2018/06/03/one-vs-all-classification/2018-06-03T16:19:21.000Z2024-09-19T21:20:30.041ZPreviously, we talked about how to build a binary classifier by implementing our own logistic regression model in Python. In this post, we're going to build upon that existing model and turn it into a multi-class classifier using an approach called one-vs-all classification.
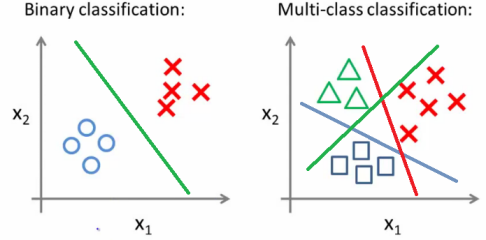
One-vs-All Classification
First of all, let me briefly explain the idea behind one-vs-all classification. Say we have a classification problem and there are $N$ distinct classes. In this case, we’ll have to train a multi-class classifier instead of a binary one.
One-vs-all classification is a method which involves training $N$ distinct binary classifiers, each designed for recognizing a particular class. Then those $N$ classifiers are collectively used for multi-class classification as demonstrated below:
We already know from the previous post how to train a binary classifier using logistic regression. So the only thing we have to do now really is to train $N$ binary classifiers instead of just one. And that’s pretty much it.
Problem & Dataset
We’re going to use this one-vs-all approach to solve a multi-class classification problem from the machine learning course thought by Andrew Ng. The goal in this problem is to identify digits from 0 to 9 by looking at 20x20 pixel drawings.
Here the number of classes $N$ is equal to 10, which is the number of different digits. We’re going to treat each pixel as an individual feature, which adds up to 400 features per image. Here are some examples from our training sample of 5000 images:
The training data is stored in a file called digits.mat. The reason that it’s a .mat file is because this problem is originally a Matlab assignment. No big deal, since it’s pretty easy to import a .mat file in Python using the loadmat function from the scipy.io module. Here’s how to do it:
1 2 3 4 5 6 7 8 9 10 11
import numpy as np import scipy.io as sio import scipy.optimize as opt
data = sio.loadmat("digits.mat") x = data['X'] # the feature matrix is labeled with 'X' inside the file y = np.squeeze(data['y']) # the target variable vector is labeled with 'y' inside the file np.place(y, y == 10, 0) # replace the label 10 with 0 numExamples = x.shape[0] # 5000 examples numFeatures = x.shape[1] # 400 features numLabels = 10# digits from 0 to 9
Let me point out two things here:
We’re using the squeeze function on the y array in order to explicitly make it one dimensional. We’re doing this because y is stored as a 2D matrix in the .mat file although it’s actually a 1D array.
We’re replacing the label 10 with 0. This label actually stands for the digit 0 but it was converted to 10 because of array indexing issues in Matlab.
Logistic Regression Recap
Remember the sigmoid, cost and cost_gradient functions that we’ve come up with while training a logistic regression model in the previous post? Here we can reuse these functions exactly as they are, because we’re going to train nothing but logistic regression models also in this problem.
The final thing we have to do before starting to train our multi-class classifier is to add an initial column of ones to our feature matrix to take into account the intercept term:
1 2
X = np.ones(shape=(x.shape[0], x.shape[1] + 1)) X[:, 1:] = x
Now we’re ready to train our classifiers. Let’s create an array to store the model parameters $\theta$ for each classifier. Note that we need 10 sets of model parameters, each consisting of 401 parameters including the intercept term:
Here we create a label vector in each iteration. We set its values to 1 where the corresponding values in y are equal to the current digit, and we set the rest of its values to 0. Hence the label vector acts as the target variable vector y of the binary classifier that we train for the current digit.
Predictions
We can evaluate the probability estimations of our optimized model for each class as follows:
This will give us a matrix of 5000 rows and 10 columns, where the columns correspond to the estimated class (digit) probabilities for all 5000 images.
However, we may need the final predictions of the optimized classifier instead of numerical probability estimations. We can find out our model’s predictions by simply selecting the label with the highest probability in each row :
1
predictions = classProbabilities.argmax(axis=1)
Now we have our model’s predictions as a vector with 5000 elements labeled from 0 to 9.
Accuracy
Finally, we can compute our model’s training accuracy by computing the percentage of successful predictions:
An accuracy of 94.5% isn’t bad at all considering we have 10 classes and a very large number of features. Still, we could do even better if we decided to use a nonlinear model such as a neural network.
If you’re still here, you should subscribe to get updates on my future articles.
]]><a href="/2018/05/19/binary-logistic-regression/" title="Previously">Previously</a>, we talked about how to build a binary classifier by implementing our own logistic regression model in Python. In this post, we're going to build upon that existing model and turn it into a multi-class classifier using an approach called one-vs-all classification.Training a Simple Binary Classifier Using Logistic Regressionhttps://utkuufuk.com/2018/05/19/binary-logistic-regression/2018-05-19T12:49:51.000Z2024-09-19T21:08:22.665ZLogistic regression is a simple classification method which is widely used in the field of machine learning. Today we’re going to talk about how to train our own logistic regression model in Python to build a a binary classifier. We’ll use NumPy for matrix operations, SciPy for cost minimization, Matplotlib for data visualization and no machine learning tools or libraries whatsoever.
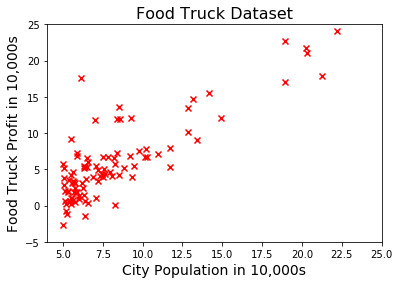
Problem & Dataset
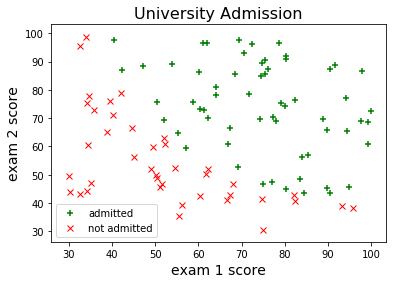
We’ll be looking at another assignment from the machine learning course taught by Andrew Ng. Our objective in this problem is to estimate an applicant’s probability of admission into a university based on his/her results on two exams. Our dataset contains some historical data from previous applicants, which we’ll use as a training sample. Let’s read the dataset file and take a look at the first few examples:
1 2 3 4 5 6 7 8
import numpy as np import matplotlib.pyplot as plt import scipy.optimize as opt
data = np.loadtxt('university_admission.txt', delimiter=",") x = data[:, 0:2] y = data[:, 2] print(data[:5])
The first two columns correspond to the exam scores and the third column indicates whether the applicant has been admitted to the university. We can visualize this data using a scatter plot:
Logistic regression is a linear model, which means that the decision boundary has to be a straight line. This can be achieved with a a simple hypothesis function in the following form:
$h_\theta(x) = g(\theta^Tx)$
where $g$ is the sigmoid function which is defined as:
$g(z) = \dfrac{1}{1 + e^{-z}}$
Here’s the Python version of the sigmoid function:
1 2
defsigmoid(z): return1 / (1 + np.exp(-z))
The numeric output of the hypothesis function $h_\theta(x)$ corresponds to the model’s confidence in labeling the input:
If the output is $0.5$, both classes are equally probable as far as the classifier is concerned.
If the output is $1$, the classifier is 100% confident about class 1.
If the output is $0$, the classifier is 100% confident about class 0.
In other words, the classifier labels the input based on whether $\theta^Tx$ is positive or negative. Of course this is based on the assumption that the treshold is selected as $0.5$.
Cost Function
In the training stage, we’ll try to minimize the cost function below:
We’re going to use the fmin_cg function from scipy.optimize to minimize our cost. fmin_cg needs the gradient of the cost function as well as the cost function itself. Here’s the formula for the cost gradient:
If you’re not familiar with fmin_cg, it might be a good idea to check out my previous post and/or the official docs before proceeding to the next section.
Training Stage
The final thing we need to do before training our model is to add an additional first column to $x$, in order to account for the intercept term $\theta_0$:
1 2
X = np.ones(shape=(x.shape[0], x.shape[1] + 1)) X[:, 1:] = x
Finally we can train our logistic regression model:
1 2
initial_theta = np.zeros(X.shape[1]) # set initial model parameters to zero theta = opt.fmin_cg(cost, initial_theta, cost_gradient, (X, y))
Optimization terminated successfully. Current function value: 0.203498 Iterations: 51 Function evaluations: 122 Gradient evaluations: 122
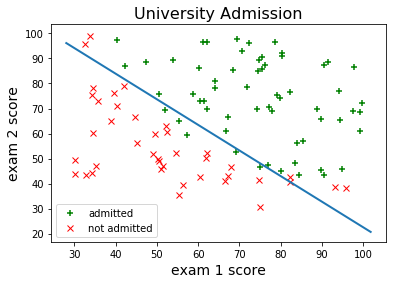
Now let’s plot the decision boundary of our optimized model:
Not bad at all. We would probably need something little more flexible than logistic regression if we wanted to come up with a more accurate classifier.
Prediction
Finally, here’s how we can predict the probability of admission for a student with arbitrary exam scores:
1 2
probability = sigmoid(np.array([1, 45, 85]) @ theta) print("For a student with scores 45 and 85, we predict an admission probability of", probability)
For a student with scores 45 and 85, we predict an admission probability of 0.776195474168
If you’re still here, you should subscribe to get updates on my future articles.
]]><p>Logistic regression is a simple classification method which is widely used in the field of machine learning. Today we’re going to talk about how to train our own logistic regression model in Python to build a a binary classifier. We’ll use <a href="http://www.numpy.org/">NumPy</a> for matrix operations, <a href="https://www.scipy.org/">SciPy</a> for cost minimization, <a href="https://matplotlib.org/">Matplotlib</a> for data visualization and no machine learning tools or libraries whatsoever.</p>Learning Curves in Linear & Polynomial Regressionhttps://utkuufuk.com/2018/05/04/learning-curves/2018-05-03T22:55:01.000Z2024-09-19T21:19:42.885ZLearning curves are very useful for analyzing the bias-variance characteristics of a machine learning model. In this post, I’m going to talk about how to make use of them in a case study of a regression problem. We’re going to start with a simple linear regression model and improve it as much as we can by taking advantage of learning curves.
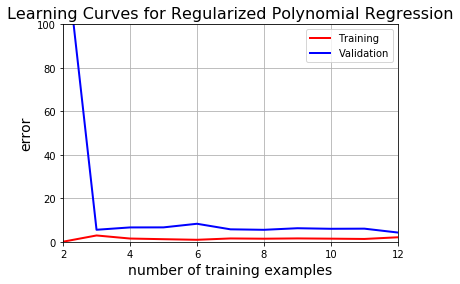
Introduction to Learning Curves
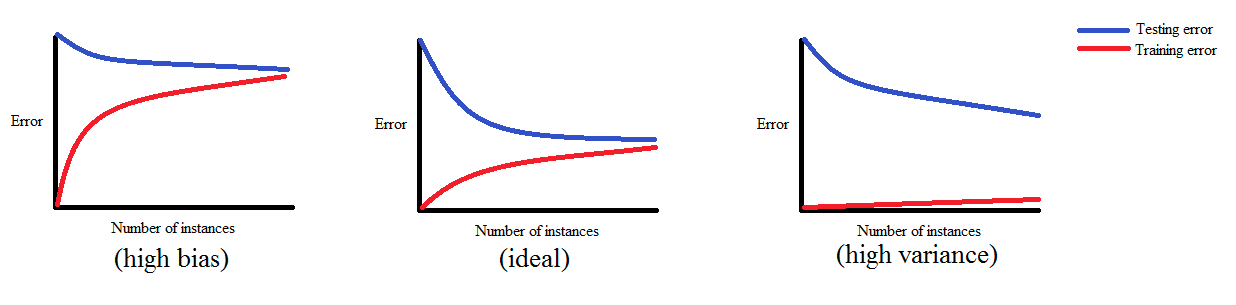
In a nutshell, learning curves show how the training and validation errors change with respect to the number of training examples used while training a machine learning model.
If a model is balanced, both errors converge to small values as the training sample size increases.
If a model has high bias, it ends up underfitting the data. As a result, both errors fail to decrease no matter how many examples there are in the training set.
If a model has high variance, it ends up overfitting the training data. In that case, increasing the training sample size decreases the training error but it fails to decrease the validation error.
The figure below demonstrates each of those cases:
Problem Definition and Dataset
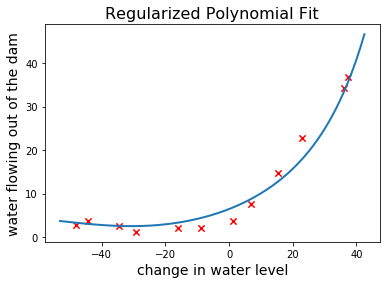
After this incredibly brief introduction, let me introduce you to today’s problem where we’ll get to see learning curves in action. It’s another problem from Andrew Ng’smachine learning course, in which the objective is to predict the amount of water flowing out of a dam, given the change of water level in a reservoir.
The dataset file we’re about to read contains historical records on the change in water level and the amount of water flowing out of the dam. The reason that it’s a .mat file is because this problem is originally a MATLAB assignment. Fortunately, it’s pretty easy to load .mat files in Python using the loadmat function from SciPy. We’ll also need NumPy and Matplotlib for matrix operations and data visualization:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import numpy as np import matplotlib.pyplot as plt import scipy.optimize as opt # we'll need this later import scipy.io as sio
# squeeze the target variables into one-dimensional arrays y_train = dataset["y"].squeeze() y_val = dataset["yval"].squeeze() y_test = dataset["ytest"].squeeze()
The dataset is divided into three samples:
The training sample consists of x_train and y_train.
The validation sample consists of x_val and y_val.
The test sample consists of x_test and y_test.
Notice that we have to explicitly convert the target variables (y_train, y_val and y_test) to one dimensional vectors, because they are stored as matrices inside the .mat file.
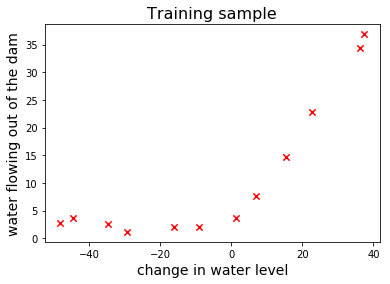
Let’s plot the training sample to see what it looks like:
1 2 3 4 5 6
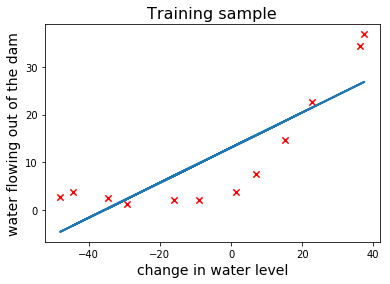
fig, ax = plt.subplots() ax.scatter(x_train, y_train, marker="x", s=40, c='red') plt.xlabel("change in water level", fontsize=14) plt.ylabel("water flowing out of the dam", fontsize=14) plt.title("Training sample", fontsize=16) plt.show()
The Game Plan
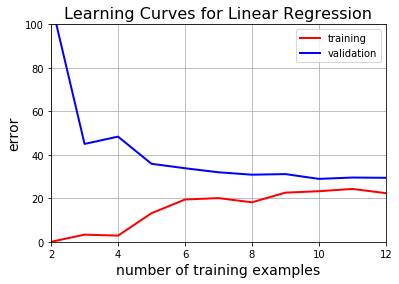
Alright, it’s time to come up with a strategy. First of all, it’s clear that there’s a nonlinear relationship between $x$ and $y$. Normally we would rule out any linear model because of that. However, we are going to begin by training a linear regression model so that we can see how the learning curves of a model with high bias look like.
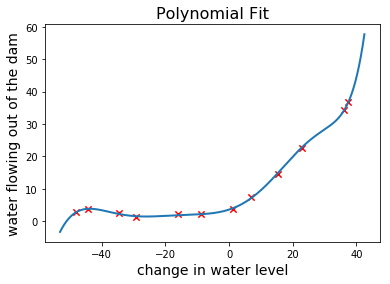
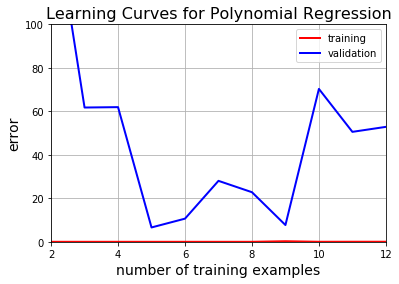
Then we’ll train a polynomial regression model which is going to be much more flexible than linear regression. This will let us see the learning curves of a model with high variance.
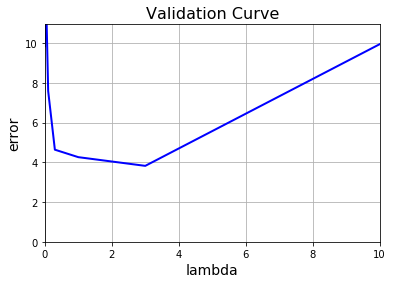
Finally, we’ll add regularization to the existing polynomial regression model and see how a balanced model’s learning curves look like.
Linear Regression
I’ve already shown you in the previous post how to train a linear regression model using gradient descent. Before proceeding any further, I strongly encourage you to take a look at it if you don’t have at least a basic understanding of linear regression.
Here I’ll show you an easier way to train a linear regression model using an optimization function called fmin_cg from scipy.optimize. You can check out the detailed documentation here. The cool thing about this function is that it’s faster than gradient descent and also you don’t have to select a learning rate by trial and error.
fmin_cg needs a function that returns the cost and another one that returns the gradient of the cost for a given hypothesis. We have to pass those to fmin_cg as function arguments. Fortunately, we can reuse some code from the previous post:
We can completely reuse the cost function because it’s independent of the optimization method that we use.
From the gradient_descent function, we can borrow the part where the gradient of the cost function is evaluated.
So here’s (almost) all we need in order to train a linear regression model:
deftrain_linear_regression(X, y): theta = np.zeros(X.shape[1]) # initialize model parameters with zeros return opt.fmin_cg(cost, theta, cost_gradient, (X, y), disp=False)
If you look at our cost function, there we evaluate the cross product of the feature matrix $X$ and the vector of model parameters $\theta$. Remember, this is only possible if the matrix dimensions match. Therefore we also need a tiny utility function to insert an additional first column of all ones to a raw feature matrix such as x_train.
1 2 3 4
definsert_ones(x): X = np.ones(shape=(x.shape[0], x.shape[1] + 1)) X[:, 1:] = x return X
Now let’s train a linear regression model and plot the linear fit on top of the training sample:
The above plot clearly shows that linear regression is not suitable for this task. Let’s also look at its learning curves and see if we can draw the same conclusion.
While plotting learning curves, we’re going to start with $2$ training examples and increase them one by one. In each iteration, we’ll train a model and evaluate the training error on the existing training sample, and the validation error on the whole validation sample:
In order to use this function, we have to resize x_val just like we did x_train:
1 2 3
X_val = insert_ones(x_val) plt.title("Learning Curves for Linear Regression", fontsize=16) learning_curves(X_train, y_train, X_val, y_val)
As expected, we were unable to sufficiently decrease either the training or the validation error.
Polynomial Regression
Now it’s time to introduce some nonlinearity with polynomial regression.
Feature Mapping
In order to train a polynomial regression model, the existing feature(s) have to be mapped to artificially generated polynomial features. Then the rest is pretty much the same drill.
In our case we only have a single feature $x_1$, the change in water level. Therefore we can simply compute the first several powers of $x_1$ to artificially obtain new polynomial features. Let’s create a simple function for this:
1 2 3 4 5
defpoly_features(x, degree): X_poly = np.zeros(shape=(len(x), degree)) for i inrange(0, degree): X_poly[:, i] = x.squeeze() ** (i + 1); return X_poly
Now let’s generate new feature matrices for training, validation and test samples with 8 polynomial features in each:
Ok, we have our polynomial features but we also have a tiny little problem. If you take a closer look at one of the new matrices, you’ll see that the polynomial features are very imbalanced at the moment. For instance, let’s look at the first few rows of the x_train_poly matrix:
As the polynomial degree increases, the values in the corresponding columns exponentially grow to the point where they differ by orders of magnitude.
The thing is, the cost function will generally converge much more slowly when the features are imbalanced like this. So we need to make sure that our features are on a similar scale before we begin to train our model. We’re going to do this in two steps:
Subtract the mean value of each column from itself and make the new mean $0$.
Divide the values in each column by their standard deviation and make the new standard deviation $1$.
It’s important that we use the mean and standard deviation values from the training sample while normalizing the validation and test samples.
Finally we can train our polynomial regression model by using our train_linear_regression function and plot the polynomial fit. Note that when the polynomial features are simply treated as independent features, training a polynomial regression model is no different than training a multivariate linear regression model:
theta = train_linear_regression(X_train_poly, y_train) plt.scatter(x_train, y_train, marker="x", s=40, c='red') plt.xlabel("change in water level", fontsize=14) plt.ylabel("water flowing out of the dam", fontsize=14) plt.title("Polynomial Fit", fontsize=16) plot_fit(min(x_train), max(x_train), train_means, train_stdevs, theta, 8)
What do you think, seems pretty accurate right? Let’s take a look at the learning curves.
1 2
plt.title("Learning Curves for Polynomial Regression", fontsize=16) learning_curves(X_train_poly, y_train, X_val_poly, y_val)
Now that’s overfitting written all over it. Even though the training error is very low, the validation error miserably fails to converge.
It appears that we need something in between in terms of flexibility. Although we can’t make linear regression more flexible, we can decrease the flexibility of polynomial regression using regularization.
Regularized Polynomial Regression
Regularization lets us come up with simpler hypothesis functions that are less prone to overfitting. This is achieved by penalizing large $\theta$ values during the training stage.
Alright we’re now ready to train a regularized polynomial regression model. Let’s set $\lambda = 1$ and plot our polynomial hypothesis on top of the training sample:
1 2 3 4 5 6
theta = train_linear_regression(X_train_poly, y_train, 1) plt.scatter(x_train, y_train, marker="x", s=40, c='red') plt.xlabel("change in water level", fontsize=14) plt.ylabel("water flowing out of the dam", fontsize=14) plt.title("Regularized Polynomial Fit", fontsize=16) plot_fit(min(x_train), max(x_train), train_means, train_stdevs, theta, 8)
It is clear that this hypothesis is much less flexible than the unregularized one. Let’s plot the learning curves and observe its bias-variance tradeoff:
This is apparently the best model we’ve come up so far.
Choosing the Optimal Regularization Parameter
Although setting $\lambda = 1$ has significantly improved the unregularized model, we can do even better by optimizing $\lambda$ as well. Here’s how we’re going to do it:
Select a set of $\lambda$ values to try out.
Train a model for each $\lambda$ in the set.
Find the $\lambda$ value that yields the minimum validation error.
Looks like we’ve achieved the lowest validation error where $\lambda = 3$.
Evaluating Test Errors
It’s good practice to evaluate an optimized model’s accuracy on a separate test sample other than the training and validation samples. So let’s train our models once again and compare test errors:
If you’re still here, you should subscribe to get updates on my future articles.
]]><p>Learning curves are very useful for analyzing the bias-variance characteristics of a machine learning model. In this post, I’m going to talk about how to make use of them in a case study of a regression problem. We’re going to start with a simple linear regression model and improve it as much as we can by taking advantage of learning curves.<br>Training a Simple Linear Regression Model From Scratchhttps://utkuufuk.com/2018/04/21/linear-regression/2018-04-21T11:20:15.000Z2024-09-19T21:19:48.268ZHey everyone, welcome to my first blog post! This is going to be a walkthrough on training a simple linear regression model in Python. I’ll show you how to do it from scratch, without using any machine learning tools or libraries. We’ll only use NumPy and Matplotlib for matrix operations and data visualization.
Problem & Dataset
We’ll look at a regression problem from a very popular machine learning course taught by Andrew Ng. Our objective in this problem will be to train a model that accurately predicts the profits of a food truck.
The first column in our dataset file contains city populations and the second column contains food truck profits in each city, both in $10,000$s. Here are the first few training examples:
We’re going to use this dataset as a training sample to build our model. Let’s begin by loading it:
1 2 3 4 5 6
import numpy as np import matplotlib.pyplot as plt
data = np.loadtxt('food_truck_data.txt', delimiter=",") x = data[:, 0] # city populations y = data[:, 1] # food truck profits
Both $x$ and $y$ are one dimensional arrays, because we have one feature (population) and one target variable (profit) in this problem. Therefore we can conveniently visualize our dataset using a scatter plot:
1 2 3 4 5 6 7
fig, ax = plt.subplots() ax.scatter(x, y, marker="x", c="red") plt.title("Food Truck Dataset", fontsize=16) plt.xlabel("City Population in 10,000s", fontsize=14) plt.ylabel("Food Truck Profit in 10,000s", fontsize=14) plt.axis([4, 25, -5, 25]) plt.show()
Hypothesis Function
Now we need to come up with a straight line which accurately represents the relationship between population and profit. This is called the hypothesis function and it’s formulated as:
where $x$ corresponds to the feature matrix and $\theta$ corresponds to the vector of model parameters.
Since we have a single feature $x_1,$ we’ll only have two model parameters $\theta_0$ and $\theta_1$ in our hypothesis function:
$h_\theta(x) = \theta_0 + \theta_1x_1$
As you may have noticed, the number of model parameters is equal to the number of features plus $1$. That’s because each feature is weighted by a parameter to control its impact on the hypothesis $h_\theta(x)$. There is also an independent parameter $\theta_0$ called the intercept term, which defines the point where the hypothesis function intercepts the $y$-axis as demonstrated below:
The predictions of a hypothesis function can easily be evaluated in Python by computing the cross product of $x$ and $\theta^T.$ At the moment we have our $x$ and $y$ vectors but we don’t have our model parameters yet. So let’s create those as well and initialize them with zeros:
1
theta = np.zeros(2)
Also, we have to make sure that the matrix dimensions of $x$ and $\theta^T$ are compatible with each other for cross product. Currently $x$ has $1$ column but $\theta^T$ has $2$ rows. The dimensions don’t match because of the additional intercept term $\theta_0.$
We can solve this issue by prepending a column to $x$ and set it to all ones. This is essentially equivalent to creating a new feature $x_0 = 1.$ This extra column won’t affect the hypothesis whatsoever because $\theta_0$ is going to be multiplied by $1$ in the cross product.
Let’s create a new variable $X$ to store the extended $x$ matrix:
1 2
X = np.ones(shape=(len(x), 2)) X[:, 1] = x
Finally, we can compute the predictions of our hypothesis as follows:
1
predictions = X @ theta
Of course, the predictions are currently all zeros because we haven’t trained our model yet.
Cost Function
The objective in training a linear regression model is to minimize a cost function, which measures the difference between actual $y$ values in the training sample and predictions made by the hypothesis function $h_\theta(x)$.
Now let’s take a look at the cost of our initial untrained model:
1
print('The initial cost is:', cost(theta, X, y))
The initial cost is: 32.0727338775
Gradient Descent Algorithm
Since our hypothesis is based on the model parameters $\theta$, we must somehow adjust them to minimize our cost function $J(\theta)$. This is where the gradient descent algorithm comes into play. It’s an optimization algorithm which can be used in minimizing differentiable functions. Luckily our cost function $J(\theta)$ happens to be a differentiable one.
So here’s how the gradient descent algorithm works in a nutshell:
In each iteration, it takes a small step in the opposite gradient direction of $J(\theta)$. This makes the model parameters $\theta$ gradually come closer to the optimal values. This process is repeated until eventually the minimum cost is achieved.
More formally, gradient descent performs the following update in each iteration:
The $\alpha$ term here is called the learning rate. It allows us to control the step size to update $\theta$ in each iteration. Choosing a too large learning rate may prevent us from converging to a minimum cost, whereas choosing a too small learning rate may significantly slow down the algorithm.
Here’s a generic implementation of the gradient descent algorithm:
1 2 3 4 5 6 7 8 9
defgradient_descent(X, y, alpha, num_iters): num_features = X.shape[1] theta = np.zeros(num_features) # initialize model parameters for n inrange(num_iters): predictions = X @ theta # compute predictions based on the current hypothesis errors = predictions - y gradient = X.transpose() @ errors theta -= alpha * gradient / len(y) # update model parameters return theta # return optimized parameters
Now let’s use this function to train our model and plot the hypothesis function:
1 2 3 4
theta = gradient_descent(X, y, 0.02, 600) # run GD for 600 iterations with learning rate = 0.02 predictions = X @ theta # predictions made by the optimized model ax.plot(X[:, 1], predictions, linewidth=2) # plot the hypothesis on top of the training data fig
Debugging
Our linear fit looks pretty good, right? The algorithm must have successfully optimized our model.
Well, to be honest, it’s been fairly easy to visualize the hypothesis because there’s only one feature in this problem.
But what if we had multiple features? Then it wouldn’t be possible to simply plot the hypothesis to see whether the algorithm has worked as intended or not.
Fortunately, there’s a simple way to debug the gradient descent algorithm irrespective of the number of features:
Modify the gradient descent function to make it record the cost at the end of each iteration.
Plot the cost history after the gradient descent has finished.
Pat yourself on the back if you see that the cost has monotonically decreased over time.
Here’s the modified version of our gradient descent function:
1 2 3 4 5 6 7 8 9 10 11
defgradient_descent(X, y, alpha, num_iters): cost_history = np.zeros(num_iters) # create a vector to store the cost history num_features = X.shape[1] theta = np.zeros(num_features) for n inrange(num_iters): predictions = X @ theta errors = predictions - y gradient = X.transpose() @ errors theta -= alpha * gradient / len(y) cost_history[n] = cost(theta, X, y) # compute and record the cost return theta, cost_history # return optimized parameters and cost history
Now let’s try learning rates $0.01$, $0.015$, $0.02$ and plot the cost history for each one:
1 2 3 4 5 6 7 8 9 10 11 12 13
plt.figure() num_iters = 1200 learning_rates = [0.01, 0.015, 0.02] for lr in learning_rates: _, cost_history = gradient_descent(X, y, lr, num_iters) plt.plot(cost_history, linewidth=2) plt.title("Gradient descent with different learning rates", fontsize=16) plt.xlabel("number of iterations", fontsize=14) plt.ylabel("cost", fontsize=14) plt.legend(list(map(str, learning_rates))) plt.axis([0, num_iters, 4, 6]) plt.grid() plt.show()
It appears that the gradient descent algorithm worked correctly for these particular learning rates. Notice that it takes more iterations to minimize the cost as the learning rate decreases.
Now let’s try a larger learning rate and see what happens:
Doesn’t look good… That’s what happens when the learning rate is too large. Even though the gradient descent algorithm takes steps in the correct direction, these steps are so huge that it’s going to overshoot the target and the cost diverges from the minimum value instead of converging to it.
Right now we can safely set the learning rate to $0.02$, because it allows us to minimize the cost and it requires relatively fewer iterations to converge.
Prediction
Now that we’ve learned how to train our model, we can finally predict the food truck profit for a particular city:
1 2 3 4
theta, _ = gradient_descent(X, y, 0.02, 600) # train the model test_example = np.array([1, 7]) # pick a city with 70,000 population as a test example prediction = test_example @ theta # use the trained model to make a prediction print('For population = 70,000, we predict a profit of $', prediction * 10000);
For population = 70,000, we predict a profit of $ 45905.6621788
If you’re still here, you should subscribe to get updates on my future articles.
]]><p>Hey everyone, welcome to my first blog post! This is going to be a walkthrough on training a simple linear regression model in Python. I’ll show you how to do it from scratch, without using any machine learning tools or libraries. We’ll only use <a href="http://www.numpy.org/">NumPy</a> and <a href="https://matplotlib.org/">Matplotlib</a> for matrix operations and data visualization.<br>